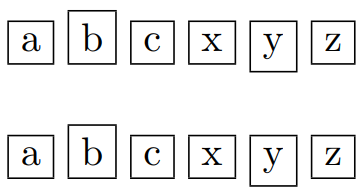निरंजन

Based on [this](https://tex.stackexchange.com/a/225920/174620) beautiful answer, I formed the following code.
```
\documentclass{article}
\usepackage{environ}
\usepackage{xparse}
\NewDocumentCommand{\myfunc}{ >{\SplitList{ }} m }{%
\ProcessList{#1}{\func}%
}
\NewDocumentCommand{\func}{m}{%
\fbox{#1} % a space follows
}
\NewEnviron{mytab}{\myfunc{\BODY}}
\begin{document}
\myfunc{a b c x y z}
\bigskip
\begin{mytab}
a b c x y z
\end{mytab}
\end{document}
```
This results as -
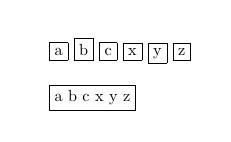
If I have used the same stuff in the command and in the environment,
1. Why does the command interprets the letters separately and environment treats them as one unit?
1. How to have the exact same result for the command and the environment?
1. Is there any in-built way in `xparse` to achieve this? I mean instead of a command like `myfunc` an environment named `myfunc` which will return the correct output?
Top Answer
joulev

> Why does the command interprets the letters separately and environment treats them as one unit?
I think this has something to do with token expansion. When `mytab` is used, `\myfunc` receive just one token in its argument, `\BODY`. There are no spaces yet so all `\*List` commands don't have any effect.
> How to have the exact same result for the command and the environment?
You have to expand `\BODY` first.
```
% arara: pdflatex
\documentclass{article}
\usepackage{environ}
\usepackage{xparse}
\NewDocumentCommand{\myfunc}{ >{\SplitList{ }} m }{%
\ProcessList{#1}{\func}%
}
\NewDocumentCommand{\func}{m}{%
\fbox{#1} % a space follows
}
\NewEnviron{mytab}{\expandafter\myfunc\expandafter{\BODY}}
\begin{document}
\myfunc{a b c x y z}
\bigskip
\begin{mytab}
a b c x y z
\end{mytab}
\end{document}
```
> Is there any in-built way in xparse to achieve this? I mean instead of a command like myfunc an environment named myfunc which will return the correct output?
Just use `b` in `xparse` instead of `environ` and it works. Why? `xparse` doesn't use a macro like `environ`, instead it uses the normal way of handling arguments: `#n`. So you don't have to worry much about expansions.
```
% arara: pdflatex
\documentclass{article}
\usepackage{xparse}
\NewDocumentCommand{\myfunc}{ >{\SplitList{ }} m }{%
\ProcessList{#1}{\func}%
}
\NewDocumentCommand{\func}{m}{%
\fbox{#1} % a space follows
}
\NewDocumentEnvironment{mytab}{b}{\myfunc{#1}}
\begin{document}
\myfunc{a b c x y z}
\bigskip
\begin{mytab}
a b c x y z
\end{mytab}
\end{document}
```
Output of both codes look the same: