निरंजन

I am having the following code with `l3regex`, but I find it too slow. What would be the most optimal method for implementing a light-weight text-replacement tool in LaTeX? It should be compliant with Unicode though.
```
\documentclass{article}
\ExplSyntaxOn
\tl_new:N \l_my_list
\cs_new_protected:Npn \replace_my_text:n #1 {
\tl_set:Nn \l_my_list {#1}
\tl_replace_all:Nnn
\l_my_list
{ abc }
{ xyz }
\tl_replace_all:Nnn
\l_my_list
{ lmn }
{ pqr }
\tl_replace_all:Nnn
\l_my_list
{ a }
{ j }
\tl_use:N \l_my_list
}
\NewDocumentCommand \replace { +m }{
\replace_my_text:n { #1 }
}
\ExplSyntaxOff
\begin{document}
\replace{%
abclmnxax%
}
\end{document}
```
Top Answer
AnonymousRabbit

The functions provided by `etl` to allow expandable replacement might be faster than their unexpandable counterparts of `tl`. However there are limitations (which are also the reason why they are faster):
- `\etl_replace_all_deep:nnn` can't distinguish some tokens (see the documentation of `etl`), and the input token list must not contain `\s__etl_stop` or `\__etl_act_result:n`
- functions defined with `\etl_new_replace_all:Nn` have
- a fixed search text, so you'll clutter the hash table if you need many
- mustn't get `\s__etl_stop` as part of the input token list
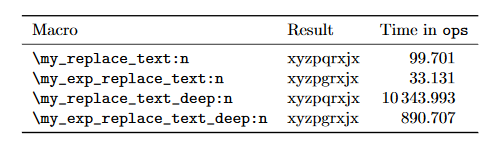
However, as I said already they might be faster (though less versatile) than the unexpandable `expl3` counterparts. Here's a comparison of using `\tl_replace_all:Nnn`, `\regex_replace_all:nnN`, `\etl_replace_all_deep:nnn`, and functions using `\etl_new_replace_all:Nn`:
```#
\documentclass{article}
\usepackage{etl, l3benchmark, booktabs, siunitx}
\ExplSyntaxOn
\tl_new:N \l_my_tmp_tl
\cs_new_protected:Npn \my_replace_text:n #1
{
\tl_set:Nn \l_my_tmp_tl {#1}
\tl_replace_all:Nnn \l_my_tmp_tl { abc } { xyz }
\tl_replace_all:Nnn \l_my_tmp_tl { lmn } { pqr }
\tl_replace_all:Nnn \l_my_tmp_tl { a } { j }
\tl_use:N \l_my_tmp_tl
}
\NewDocumentCommand \replace { +m }
{ \my_replace_text:n { #1 } }
\etl_new_replace_all:Nn \__my_exp_replace_abc:nn { abc }
\etl_new_replace_all:Nn \__my_exp_replace_lmn:nn { lmn }
\etl_new_replace_all:Nn \__my_exp_replace_a:nn { a }
\cs_generate_variant:Nn \__my_exp_replace_a:nn { e }
\cs_generate_variant:Nn \__my_exp_replace_lmn:nn { e }
\cs_new:Npn \my_exp_replace_text:n #1
{
\__my_exp_replace_a:en
{
\__my_exp_replace_lmn:en
{ \__my_exp_replace_abc:nn {#1} { xyz } }
{ pgr }
}
{ j }
}
\NewExpandableDocumentCommand \Replace { +m }
{ \my_exp_replace_text:n {#1} }
\cs_new_protected:Npn \my_replace_text_deep:n #1
{
\tl_set:Nn \l_my_tmp_tl {#1}
\regex_replace_all:nnN { abc } { xyz } \l_my_tmp_tl
\regex_replace_all:nnN { lmn } { pqr } \l_my_tmp_tl
\regex_replace_all:nnN { a } { j } \l_my_tmp_tl
\tl_use:N \l_my_tmp_tl
}
\NewDocumentCommand \replaceall { +m }
{ \my_replace_text_deep:n {#1} }
\cs_generate_variant:Nn \etl_replace_all_deep:nnn { e }
\cs_new:Npn \my_exp_replace_text_deep:n #1
{
\etl_replace_all_deep:enn
{
\etl_replace_all_deep:enn
{ \etl_replace_all_deep:nnn {#1} { abc } { xyz } }
{ lmn }
{ pgr }
}
{ a }
{ j }
}
\NewExpandableDocumentCommand \Replaceall { +m }
{ \my_exp_replace_text_deep:n {#1} }
\cs_new_protected:Npn \my_benchmark:N #1
{
\texttt { \token_to_str:N #1 } &
#1 { abclmnxax }
\benchmark_silent:n { \hbox_set:Nn \l_tmpa_box { #1 { abclmnxax } } } &
\fp_use:N \g_benchmark_ops_fp
\\
}
\begin{document}
\begin{tabular}{llS[table-format=4.3,round-precision=3,round-mode=places]}
\toprule
Macro & Result & {Time~ in~ \texttt{ops}} \\
\midrule
\my_benchmark:N \my_replace_text:n
\my_benchmark:N \my_exp_replace_text:n
\my_benchmark:N \my_replace_text_deep:n
\my_benchmark:N \my_exp_replace_text_deep:n
\bottomrule
\end{tabular}
\end{document}
```
Note that the two macros with `_deep` in their name can replace things inside of braced groups (unlike the other two), and their search text can contain braces and macro parameter tokens (unlike the other two).