निरंजन

I am trying to understand how the `\SplitList` is processed in `xparse`. I formed a simple code like following for initial testing.
```
\documentclass{article}
\NewDocumentCommand{\processedfoo}{ m }{%
\textbf{#1}%
}
\NewDocumentCommand{\foo}{ >{\SplitList{ }} m }{%
\ProcessList{#1}{\processedfoo}%
}
\begin{document}
\foo{a b c}
\end{document}
```
but by looking at the output it is not very clear to me what exactly is happening. There can be two possibilities:
1. The character used as the separator, i.e., `␣` in this case, is removed from the input and the remaining part, i.e., `abc` in this case, is passed to the function mentioned as the second argument of `\ProcessList`, which should result in something like `\textbf{abc}`.
2. The separator character is removed from the input, but every single item is passed separately to the function one after the other. In this case, it would be `\textbf{a}\textbf{b}\textbf{c}`.
Which of the above two is exactly happening? (Or is something else happening?)
Top Answer
frougon

Just add some punctuation to your `\processedfoo` and you'll see it's applied to each element of the first argument of `\ProcessList`:
```
\documentclass{article}
\NewDocumentCommand{\processedfoo}{ m }{%
\textbf{.#1,}%
}
\NewDocumentCommand{\foo}{ >{\SplitList{ }} m }{%
\ProcessList{#1}{\processedfoo}%
}
\begin{document}
\foo{a b c}
\foo{{foo bar} baz quux}
\end{document}
```
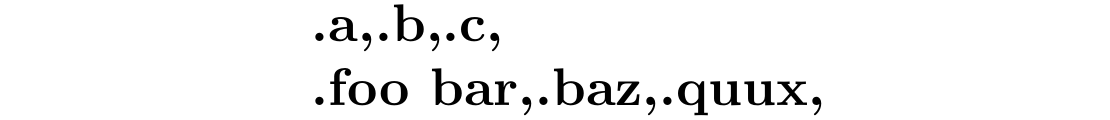
For efficiency reasons, you may want to define `\processedfoo` with either `\newcommand*` or something like this (and change the name):
```
\ExplSyntaxOn
\cs_new_protected:Npn \__my_process_element:n #1
{
\textbf { .#1, }
}
\cs_new_eq:NN \processedfoo \__my_process_element:n
\ExplSyntaxOff
```
This is because `\NewDocumentCommand` and friends are intended for user-level macros; the macros they define have more overhead than those defined with `\cs_new:Npn`, `\cs_new_protected:Npn`, etc., which are closer to `\def`, `\protected\def` and `\newcommand*`.
# Note regarding `\newcommand`
`\newcommand*` is similar to `\def`, but with less flexibility in the argument specification (no delimited arguments, in particular). On the other hand:
- it errors out in case the macro is already defined;
- it can handle one optional argument, which `\def` doesn't unless you code it by hand.
Macros defined with `\newcommand` or `\newcommand*` are never `\protected`, therefore they are expanded inside `\edef`, `\write`, `\message`, etc. (for better or worse).
Macros defined with `\newcommand` or `\newcommand*` are “robust” **only if they accept an optional argument** implemented in the normal LaTeX2e way, i.e. using `\newcommand{\foo}[n][...]{...}` (rationale: this test for the presence of the optional argument doesn't work in expansion-only contexts). “Robust” macros are:
- (usually undesirable) expanded inside `\edef`, `\write`, `\message`, etc.;
- (on purpose) not expanded inside LaTeX's `\protected@edef`, `\protected@write` and friends.
This “robustness” concept is a LaTeX mechanism that allowed to automatically prevent expansion in unwanted places for selected macros before the `\protected` primitive was added to TeX engines (which first appeared in e-TeX, AFAIK). (I believe `\protected` would have been used if available at that time; please correct me if this is not the case, as I wasn't using TeX back then. :))
# More fun with space tokens
Recreation time: how does `\SplitList` behave if the argument it processes contains several *consecutive* space tokens?
Providing such an argument is not quite straightforward, but there are many ways (note that in `\foo{ }`, even if one puts many spaces inside the braces, the argument tokenized by TeX will contain only one space token). In `expl3`, one can for instance obtain two consecutive space tokens by doing one expansion step on `\use:nn { } { }`; indeed, `\use:nn` is defined like so:
```
$ latexdef use:nn
\use:nn:
\long macro:#1#2->#1#2
```
There is another way that works as well for 42 consecutive space tokens, using `\prg_replicate:nn`:
```
\documentclass{article}
\ExplSyntaxOn
\cs_new_protected:Npn \__my_process_element:n #1
{
\textbf {.#1,}
}
\cs_new_eq:NN \processOneElement \__my_process_element:n
\cs_new_eq:NN \replicate \prg_replicate:nn
\ExplSyntaxOff
\NewDocumentCommand{\foo}{ >{\SplitList{ }} m }{%
\ProcessList{#1}{\processOneElement}%
}
\begin{document}
\edef\tmp{%
\foo{\replicate{2}{ }}%
}%
\tmp
\end{document}
```
Inside the `\edef`, `\foo` isn't expanded because `\NewDocumentCommand` defines it as a `\protected` macro. Therefore, after the `\edef`, the replacement text of the `\tmp` macro is `\foo{ }`, where there are **two** consecutive space tokens inside the braces (you can verify with `\show\tmp`).
The output of the previous document is:

which shows that `\SplitList` rightfully found three empty items separated by the two space tokens. With `\replicate{42}{ }`, if you feel like counting: :-)