निरंजन

I am trying to understand how the shipping of arguments happens in xparse.
While preparing an answer for [this](https://tex.stackexchange.com/q/627980/174620) SE question, I wrote the following code first.
```
\documentclass{article}
\usepackage{xparse}
\usepackage{listings}
\NewDocumentEnvironment{enumlike}{ +b }
{%
\begin{quote}
#1
\end{quote}%
}{}
\begin{document}
\begin{enumlike}
abcd efgh
abcd efgh
\begin{enumlike}
pqrs wxyz
pqrs wxyz
\end{enumlike}
\end{enumlike}
\end{document}
```
I tried to add an `lstlisting` (*an* because I pronounce it as el-es-tee-listing; how do you pronounce it? Why the name is so weird? :joy:) environment which failed.
It didn't take much time to realize that this issue is because the `lstlisting` thing is shipped as an argument in this case (`+b`). Therefore I wrote the following which worked.
```
\documentclass{article}
\usepackage{listings}
\newenvironment{enumlike}{%
\begin{quote}%
}{%
\end{quote}%
}
\begin{document}
\begin{enumlike}
\begin{lstlisting}
#!/bin/usr
echo "hello world"
\end{lstlisting}
abcd efgh
abcd efgh
\begin{enumlike}
\begin{lstlisting}
#!/bin/usr
echo "hello world"
\end{lstlisting}
pqrs wxyz
pqrs wxyz
\end{enumlike}
\end{enumlike}
\end{document}
```
Technically I understand that the first argument of the `\newenvironment` is inserted before the content, the second one is inserted after the content, so the content is kinda in-situ. Whereas with `+b`, I catch the `lstlisting` code as an argument and ship it to a desired place, but why it fails? What is the TeXnical explanation for these setups to differ in the outputs?
Top Answer
Skillmon

The answer is the same reason why `\textit{\verb|\abc|}` doesn't work.
Upon reading TeX assigns a category code to every token, a token is always two values, character code and category code (leaving out other token types such as macros for simplification). When TeX scans an argument it assigns category codes (we often call this scanning process tokenisation/tokenization).
These category codes are *fixed* once they are assigned and can't be changed (simplification, there are possibilities to change them, e.g., with `\tl_replace_all:Nnn` or `regex` or (and this is by far the most complicated) `\scantokens`).
When you define a new environment (traditionally) LaTeX2e does never look at the contents of the environment. The `\NewDocumentEnvironment` interface changes this behaviour. If you don't use a `b` argument this isn't changed, you're still just defining code that is run at `\begin` and at `\end` without ever looking at the contents. But with the `b` type what really is done is that everything up to `\end{<environment>}` is read as an argument, hence tokenised.
And once something is tokenised the category codes can't be changed, but `listings` relies on changing category codes to do its magic (and it will try to change the category codes, but that wouldn't work out as the tokens then read are already tokenised so the new category codes assigned by `listings` don't take effect).
Answer #2
Skillmon
You could build something yourself that'll collect your environment body.
For instance the following defines an macro `\collectverbenv` that you can use at the end of the `\begin` part of an environment.
The macro supports two modes:
1. Process every line on its own (and maybe store it)
2. Simply store the lines in an internal variable (you can then get the contents into another variable with another macro); you can add contents to the start and end of each line in that mode.
The interface is not (yet) very pretty, and you need a bit of work to make this work to forward things to `lstlisting` (or similar environments).
The macro supports ignoring the first *n* lines (you should always set this to 1, the line containing `\begin{<env>}`), and it supports collecting an optional argument inside brackets with normal category codes (that part is actually non-trivial, you can't use a normal `O`-type argument in `\NewDocumentEnvironment` as that would freeze the category code of the first token in the environment, which might not be the optional argument).
In order to use this to collect the body of an environment which should then be send on to another verbatim environment (like `lstlistings`) we need to build a bit of TeX hacking in the form of `\scantokens`. Also we need to add the line endings back in.
`\scantokens` is a nasty little primitive, it behaves as if you wrote its argument into a file (without expansion) and read the contents back in while being fully expandable, the issue is that this also contains the EOF, and introduces a space at its end. We locally use `\everyeof={\noexpand}` to solve this issue (this way the space will not end up in the input, and the EOF will do no harm). You can search for a bit more of explanations across the web.
```
\documentclass[]{article}
\usepackage{listings}
\ExplSyntaxOn
\cs_new_eq:NN \__collectverbenv_processor:n \q_nil
\keys_define:nn { collectverbenv }
{
process .code:n = \cs_set:Npn \__collectverbenv_processor:n ##1 {#1}
,bol .tl_set:N = \l__collectverbenv_bol_tl
,eol .tl_set:N = \l__collectverbenv_eol_tl
,opt .tl_set:N = \l__collectverbenv_opt_arg_tl
,ignore .int_set:N = \l__collectverbenv_ignore_int
,env .tl_set:N = \l__collectverbenv_env_tl
,env .initial:o = \cs:w @currenvir \cs_end:
,no-process .code:n = \cs_set_eq:NN \__collectverbenv_processor:n \q_nil
,no-process .value_forbidden:n = true
}
\NewDocumentCommand \collectverbenvstore { s +m }
{
\tl_put_right:Nx \l__collectverbenv_body_tl
{
\IfBooleanF {#1} { \exp_not:o \l__collectverbenv_bol_tl }
\exp_not:n {#2}
\IfBooleanF {#1} { \exp_not:o \l__collectverbenv_eol_tl }
}
}
\NewDocumentCommand \collectverbenvretrieve { m }
{
\cs_set_eq:NN #1 \l__collectverbenv_body_tl
}
\NewDocumentCommand \collectverbenv { +m }
{
\keys_set:nn { collectverbenv } {#1}
\tl_clear:N \l__collectverbenv_body_tl
\group_begin:
\__collectverbenv_set_catcodes:
\tl_if_empty:NTF \l__collectverbenv_opt_arg_tl
\__collectverbenv_collect:w
\__collectverbenv_opt_arg:w
}
\cs_new_protected:Npn \__collectverbenv_set_catcodes:
{
\cs_set_eq:NN \do \char_set_catcode_other:N
\dospecials
\char_set_catcode_active:N \^^M
}
\group_begin:
\char_set_catcode_active:N \^^M
\cs_new_protected:Npn \__collectverbenv_collect:w #1 ^^M
{
\__collectverbenv_collect_check_end:n {#1}
\int_compare:nNnTF \l__collectverbenv_ignore_int > \c_zero_int
{
\int_decr:N \l__collectverbenv_ignore_int
}
{
\cs_if_eq:NNTF \__collectverbenv_processor:n \q_nil
{
\tl_put_right:Nx \l__collectverbenv_body_tl
{
\exp_not:o \l__collectverbenv_bol_tl
#1
\exp_not:o \l__collectverbenv_eol_tl
}
}
{ \__collectverbenv_processor:n {#1} }
}
\__collectverbenv_collect:w
}
\group_end:
\exp_args:NNo
\cs_new_protected:Npn \__collectverbenv_opt_arg:w
{
\use_i_ii:nnn \peek_charcode:NTF []
\__collectverbenv_opt_arg_auxi:w
{
\group_end:
\exp_after:wN \cs_set:Npn \l__collectverbenv_opt_arg_tl {}
\group_begin:
\__collectverbenv_set_catcodes:
\__collectverbenv_collect:w
}
}
\cs_new_protected:Npn \__collectverbenv_opt_arg_auxi:w
{
\group_end:
\__collectverbenv_opt_arg_auxii:w
}
\NewDocumentCommand \__collectverbenv_opt_arg_auxii:w { O{} }
{
\exp_after:wN \tl_set:Nn \l__collectverbenv_opt_arg_tl {#1}
\group_begin:
\__collectverbenv_set_catcodes:
\__collectverbenv_collect:w
}
\cs_new_protected:Npn \__collectverbenv_collect_check_end:n #1
{
\str_set:Nn \l_tmpa_str {#1}
\str_remove_all:Nn \l_tmpa_str { ~ }
\str_if_eq:eeT
\l_tmpa_str
{ \token_to_str:N \end { \l__collectverbenv_env_tl } }
\__collectverbenv_collect_end:w
}
\cs_new:Npn \__collectverbenv_collect_end:w #1 \__collectverbenv_collect:w
{
\exp_args:NNNo
\group_end:
\tl_set:Nn \l__collectverbenv_body_tl \l__collectverbenv_body_tl
\exp_args:Ne \end { \l__collectverbenv_env_tl }
}
\tl_new:N \l__collectverbenv_body_tl
\ExplSyntaxOff
\newenvironment{exampleA}
{%
\minipage{\linewidth}
\ttfamily
\collectverbenv{process={\noindent\fbox{##1}\par},ignore=1}%
}
{%
\endminipage
}
\ExplSyntaxOn
\tl_new:N \l_exampleB_opt_tl
\tl_new:N \l_exampleB_endline_tl
\NewDocumentEnvironment { exampleB } { }
{
\tl_set:Nx \l_exampleB_endline_tl { \char_generate:nn \endlinechar { 12 } }
\collectverbenv
{
bol = AA % <- use whatever you need as a marker for a start of the line
,eol = \l_exampleB_endline_tl % <- needed to rebuild the list
,ignore = 1 % <- first line (the one containing \begin) is ignored
,opt = \l_exampleB_opt_tl % <- collect an optional argument
}
}
{
\group_begin:
\collectverbenvretrieve \l_tmpa_tl
\everyeof={\noexpand}
\exp_args:Nx \scantokens
{
\token_to_str:N \begin{lstlisting}
[{ \exp_not:o \l_exampleB_opt_tl }]
\l_exampleB_endline_tl
\l_tmpa_tl
\l_exampleB_endline_tl
\token_to_str:N \end{lstlisting}
}
\group_end:
}
\ExplSyntaxOff
\begin{document}
\noindent
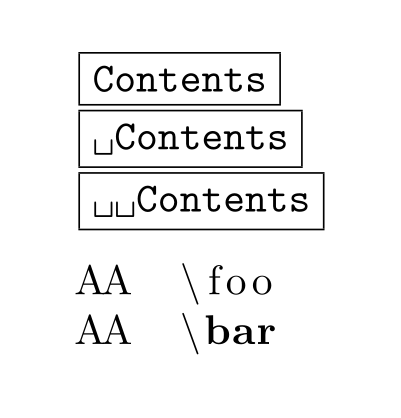
\begin{exampleA}
Contents
Contents
Contents
\end{exampleA}
\begin{exampleB}[language=TeX]
\foo
\bar
\end{exampleB}
\end{document}
```
----
I posted this code also at https://tex.stackexchange.com/a/628255/117050