I didn't want to write an answer but this appears to be too long for a comment (can't see the bottom of it anymore...).
I fully agree with [Skillmon](https://topanswers.xyz/transcript?room=1462&id=76781#c76781) here. My advice to the OP, if you have enough time:
1. Read the TeXbook and program some things in TeX. At this point, you should understand the difficulties this entails (basic data structures, parsing of “text,” flow control, floating point computations that exceed 16383.99999...). In many cases, the life saver is an e-TeX or pdfTeX primitive, if not LuaTeX entirely—all of which aren't part of Knuth's TeX, thus outside the scope of the TeXbook.
2. Look at how LaTeX2e makes this easier: not much. Some *packages* can help a little bit (`etoolbox`, `xifthen`, `intcalc` and a few other packages from Heiko Oberdiek; the PGF bundle...). Apart from PGF, it's all scattered. Even PGF is scattered in some places (think about usage of the `fpu` in `pgfmath`, when trying to do smart things with `pgfplots`: it's always doable but can be tricky).
3. Read [expl3.pdf](http://mirrors.ctan.org/macros/latex/contrib/l3kernel/expl3.pdf), skim through [l3styleguide.pdf](http://mirrors.ctan.org/macros/latex/contrib/l3kernel/l3styleguide.pdf), except section 2, which is for people using `l3doc` for literate TeX programming; and finally, read the parts of [interface3.pdf](http://mirrors.ctan.org/macros/latex/contrib/l3kernel/interface3.pdf) that you need for a given task. There you'll see many high-level functions easy to use and *cooperating* with each other, some unified programming environment. For instance, when `\regex_extract_once:nnNTF` extracts match groups for a regular expression, it uses a `seq` variable to store the matched tokens and the groups. `seq` variables are standard `expl3` sequences, so if you had already learnt to work with them, it's very easy to use the result of `\regex_extract_once:nnNTF` (you have `\seq_get_left:NN` to retrieve the first element and store it in a macro aka `tl` var, `\seq_pop_left:NN` to do the same and remove the element, `\seq_item:Nn` to expandably get the *n*th item in the input stream, where *n* is an arbitrary *integer expression* as described in the `l3int` chapter of the same [interface3.pdf](http://mirrors.ctan.org/macros/latex/contrib/l3kernel/interface3.pdf), e.g., `5 +
4 * \l_my_int - ( 3 + 4 * 5 )` with standard priority rules, etc.). It's all like that, unity.
4. Don't fear wasting time learning TeX programming before `expl3`: TeX is such a strange beast, that knowing its essential rules is probably a must in order to make sense of the `expl3` docs. (I think it helps a lot to understand the difference between expansion and execution(*), the effect of grouping, the difference between local and global assignments, to realize that `x` expansion is what `\edef` does, `e` expansion is what `\expanded` does, `\exp_not:n` is `\unexpanded`, `f` expansion is what you would obtain after `` \romannumeral`\^^@ ``, `o` expansion is what you would do with an `\expandafter`, that TeX always expands tokens recursively when processing a `\csname`, reading a ⟨number⟩, a ⟨dimen⟩ or a ⟨glue⟩, etc).
The problem with the TeXbook for this kind of learning is that its goal is not to teach TeX programming, rather typesetting using TeX for trained professionals. It does teach a lot that is useful for programming, but in order to really understand the points made by the author, you may need to read some things very carefully, twice or more, and sometimes use a search engine or experiment by yourself to understand things better.
I'm definitely not an `expl3` expert, but an example of some task that `expl3` makes easy to perform efficiently could be: “[How to count *n* things?](https://topanswers.xyz/tex?q=1291)”. My solution there uses very natural `expl3` tools to:
- incrementally build a mapping from each of the obtained values to the number of times it was obtained (I use a “property list,” aka `l3prop`);
- create a sequence of “ordered pairs” of the form `{n}{count}` from it, and very simply sort it using the first component of each ordered pair as a sorting criterion (one could as easily sort it according to the second component, since `\seq_sort:Nn`'s second argument tells how two elements compare to each other, and `\seq_sort:Nn` doesn't assume anything about the elements of the sequence);
- iterate over the sorted sequence to build a `tl` var—a simple macro—that contains the interesting data (frequencies obtained by dividing each *count* by the number of samples), properly formatted for direct use inside the table we wanted to produce.
Another thing that is highly non-trivial to do without `expl3`, IMHO: what the `l3regex` module can do: it is much more than a “simple” regular expression engine, which pdfTeX's `\pdfmatch` primitive provides (and would already be quite difficult to implement with Knuth's TeX). `l3regex` has been designed to handle the particular nature of TeX's input: not a stream of characters, but a stream of tokens, namely:
- explicit character tokens with a character and a category code attached;
- control sequence tokens.
`l3regex` regular expressions allow one to match against precise tokens, not just character codes. That is why the syntax is a bit more complicated than for traditional regexps, which many people already find difficult. But if you understand the nature of TeX's input stream after the tokenization stage, are used to regular expressions in other languages (Perl, Python, sed, Bash, C++...) and read the `l3regex` documentation which has many examples, it should all make sense!
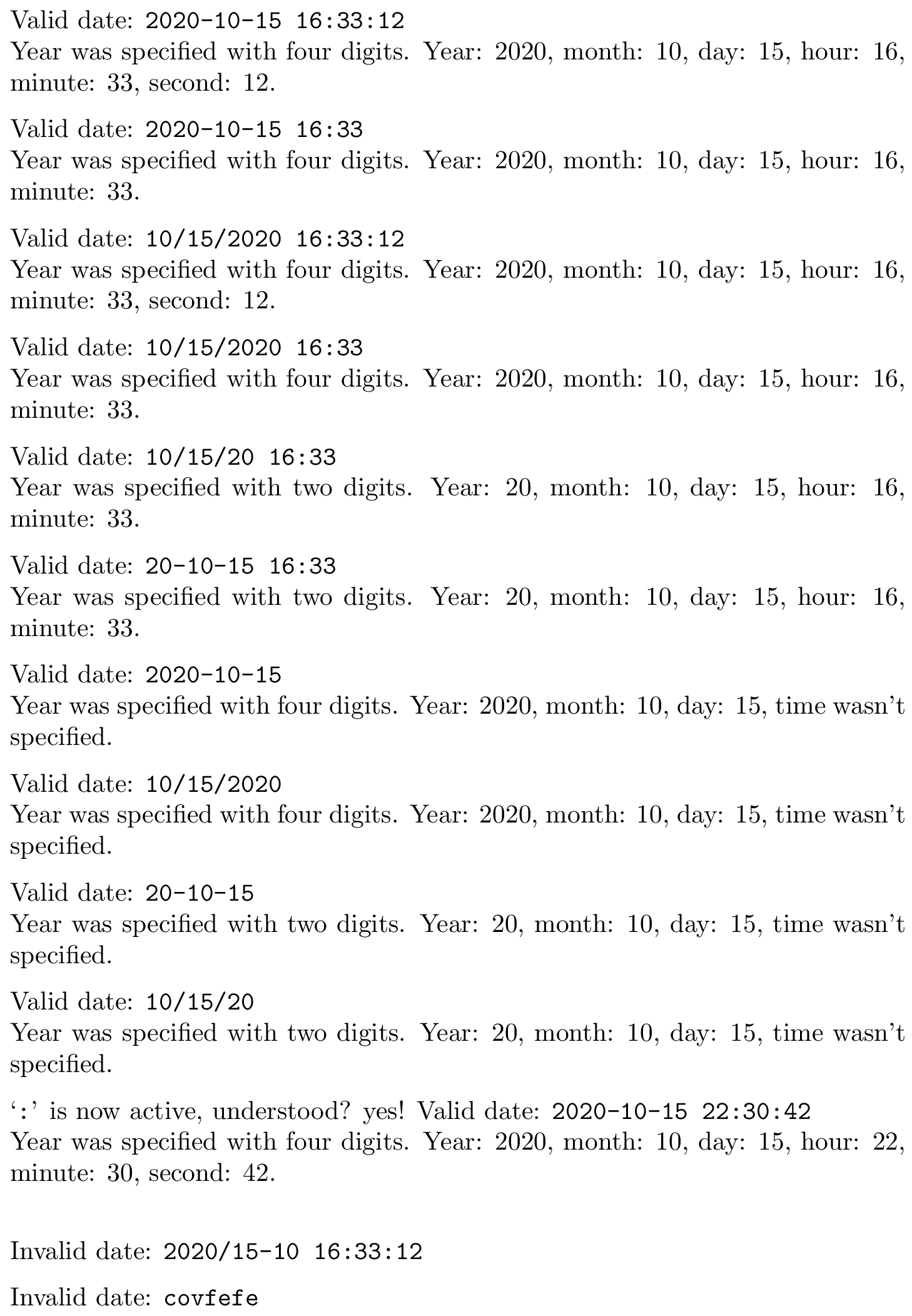
For instance, regexps make it trivial to parse a date in (YY)YY-MM-DD HH:MM:SS format. As an example of the power of regexps, let's make this more complicated and define a single regular expression that can validate, in a single call:
- a date in (YY)YY-MM-DD format (“ISO” style, except I believe actual ISO 8601 mandates four-digit years);
- a date in MM/DD/(YY)YY format (“US” style);
- a date in either of these formats followed by at least one space, then by a time in HH:MM(:SS) format.
Of course, parenthesized things are optional in this informal description. I won't verify that hours are < 24, minutes < 60, etc. to avoid making the thing too long (it is already a bit...). All the rest is verified. With the `l3regex` functions, one could very easily go further and for instance count all occurrences of such a “datetime” in a given token list regardless of the grouping level it appears in, replace all such occurrences, etc.
```
\documentclass{article}
% When these are uncommented and compilation is done with pdflatex, ':' is an
% active character in the whole 'document' environment.
% \usepackage[T1]{fontenc}
% \usepackage[french]{babel}
\usepackage{xparse} % not necessary with LaTeX 2020-10-01 or later
\ExplSyntaxOn
% Compile the regexp (optional; speeds things up if it is used many times).
\regex_const:Nn \c_my_datetime_regex
{
\A % anchor match at the start of the “string”
( (\d{2} | \d{4}) (\-) (\d\d) \- (\d\d) |
% 1 2 3 4 5 <--- captured group numbers
(\d\d) \/ (\d\d) \/ (\d{2} | \d{4})
% 6 7 8
)
% optionally followed by: one or more spaces plus time in HH:MM(:SS) format
% The ':' separators can have category Other (12) or Active (13).
(?: \ + ( (\d\d) \c[OA]\: (\d\d) (?: \c[OA]\: (\d\d) )? ) )?
% 9 10 11 12
\Z % we must be at the end of the “string”
}
\seq_new:N \l__my_result_seq
% Return match group number #1 (an integer expression) from \l__my_result_seq
\cs_new:Npn \__my_group:n #1 { \seq_item:Nn \l__my_result_seq { 1 + (#1) } }
% Generate conditional variants \tl_if_empty:eF and \tl_if_empty:eTF
\prg_generate_conditional_variant:Nnn \tl_if_empty:n { e } { F, TF }
% Is the date in US or in ISO 8601 style?
\prg_new_conditional:Npnn \my_if_US_style: { T, F, TF }
{
\tl_if_empty:eTF { \__my_group:n { 3 } }
{ \prg_return_true: }
{ \prg_return_false: }
}
% Define \__my_get_year:, \__my_get_month: and \__my_get_day:.
% The year is captured group number 8 in US style, number 2 in ISO, style, etc.
\clist_map_inline:nn { { year, 8, 2 }, { month, 6, 4 }, { day, 7, 5 } }
{
\cs_new:cpn { __my_get_ \clist_item:nn {#1} { 1 } : }
{
\my_if_US_style:TF
{ \__my_group:n { \clist_item:nn {#1} { 2 } } }
{ \__my_group:n { \clist_item:nn {#1} { 3 } } }
}
}
% Define \__my_get_{time, hour, minute, second}:.
% Yes, one could simply use what precedes, but what follows will be faster upon
% use, since there is no condition to evaluate.
\clist_map_inline:nn
{ { time, 9 }, { hour, 10 }, { minute, 11 }, { second, 12 } }
{
\cs_new:cpn { __my_get_ \clist_item:nn {#1} { 1 } : }
{
\__my_group:n { \clist_item:nn {#1} { 2 } }
}
}
\cs_new_protected:Npn \__my_print_verbatim_date:n #1
{
% \tl_to_str:n neutralizes catcodes (':' could be active in French...)
\texttt { \tl_to_str:n {#1} }
}
\cs_generate_variant:Nn \tl_count:n { f } % generate variant \tl_count:f
\cs_new_protected:Npn \my_describe_datetime:n #1
{
\regex_extract_once:NnNTF \c_my_datetime_regex {#1} \l__my_result_seq
{
Valid~date:~\__my_print_verbatim_date:n {#1} \\
Year~was~specified~with~
\int_case:nnF { \tl_count:f { \__my_get_year: } }
{
{ 2 } { two }
{ 4 } { four }
}
{ this~place~is~unreachable }
\c_space_token digits. \c_space_token
Year:~ \__my_get_year: , \c_space_token
month:~ \__my_get_month: , \c_space_token
day:~ \__my_get_day: , \c_space_token
\tl_if_empty:eTF { \__my_get_time: }
{ time~wasn't~specified. }
{
hour:~ \__my_get_hour:, \c_space_token
minute:~\__my_get_minute:
\tl_if_empty:eF { \__my_get_second: }
{ ,~ second:~ \__my_get_second: }
. % final period. :-)
}
}
{ Invalid~date:~\__my_print_verbatim_date:n {#1} }
\par\medskip
}
% Document-level command
\NewDocumentCommand \myDescribeDateTime { m }
{ \my_describe_datetime:n {#1} }
\ExplSyntaxOff
\begin{document}
\setlength{\parindent}{0pt}
\myDescribeDateTime{2020-10-15 16:33:12}
\myDescribeDateTime{2020-10-15 16:33}
\myDescribeDateTime{10/15/2020 16:33:12}
\myDescribeDateTime{10/15/2020 16:33}
\myDescribeDateTime{10/15/20 16:33}
\myDescribeDateTime{20-10-15 16:33} % not ISO 8601
\myDescribeDateTime{2020-10-15}
\myDescribeDateTime{10/15/2020}
\myDescribeDateTime{20-10-15}
\myDescribeDateTime{10/15/20}
{ % Make ':' active as with \usepackage[french]{babel} under pdfTeX.
\catcode`\:=13 \def:{yes!} `\texttt{\string:}' is now active, understood? :
\myDescribeDateTime{2020-10-15 22:30:42}
}
\bigskip
\myDescribeDateTime{2020/15-10 16:33:12} % incorrect
\myDescribeDateTime{covfefe} % also incorrect
\end{document}
```
Another example could be [this answer of Skillmon](https://tex.stackexchange.com/a/567676/73317) where you can compare an `expl3` approach with one based on LaTeX2e, and decide for yourself which one is easier to read and write.
(*) Unfortunately, Knuth prefers to talk about “mouth” and “stomach” instead of expansion and execution in the TeXbook, but this is exactly the same. This just illustrates the fact that, IMHO, these things were not the main objectives of the book for him.