Forrest

Consider the following <https://dbfiddle.uk/?rdbms=sqlserver_2019&fiddle=ed52053f320f9d35f575efe6c14a0e59> ``` CREATE TABLE #A (ID int primary key) CREATE TABLE #B (ID int primary key) INSERT #A SELECT TOP (10) ROW_NUMBER() OVER(ORDER BY 1/0) FROM sys.columns INSERT #B SELECT TOP (10) ROW_NUMBER() OVER(ORDER BY 1/0) FROM sys.columns SELECT * FROM #A a JOIN #B b ON a.ID = b.ID WHERE a.ID IN (1,10) ``` There are two seeks into #A to find the IDs, each followed by a seek in #B to find the matching ID. However, there's an extra predicate in the seek on #B. 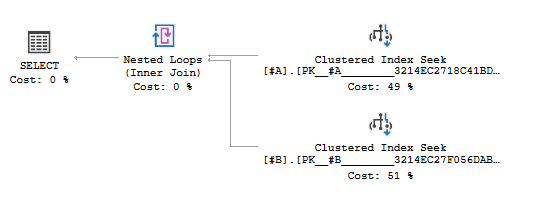 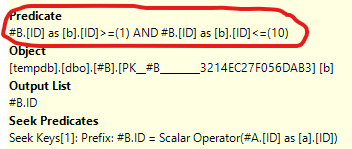 Shouldn't the Seek Predicate be enough to guarantee correctness? What's the purpose of this extra predicate?