Joe Obbish

Consider the following SQL Server query:
SELECT TOP (1) Id
FROM dbo.HeapForMyTopQuestion
WHERE Id = 258; -- Lamak's favorite number
dbo.HeapForMyTopQuestion is a uncompressed heap with no indexes with 100 million rows. There are no rows in the table that match the predicate. Code to create and populate the table is at the bottom of this Top Question.
I get a trivial query plan with a row goal:
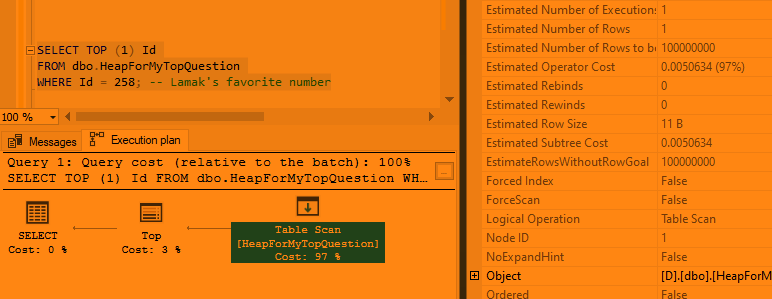
This is the worst possible plan choice for this query because no rows match the predicate. All rows will be scanned from the table in a serial plan. At the very least, we could do better with query parallelism. I can disable the row goal optimization with a query hint:
SELECT TOP (1) Id
FROM dbo.HeapForMyTopQuestion
WHERE Id = 258
AND (SELECT 1) = 1
OPTION (USE HINT('DISABLE_OPTIMIZER_ROWGOAL'));
This does remove the row goal optimization and the query cost very slightly changes, but I still get the same query plan as before. I don't understand the operator costing of the scan:
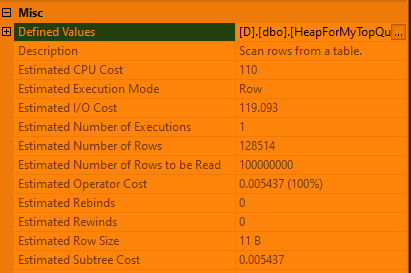
It appears that the scan cost is still discounted by the TOP operator. Isn't that exactly what a row goal is? Quoting the admittedly brief summary from [Setting and Identifying Row Goals in Execution Plans
](https://sqlperformance.com/2018/02/sql-plan/setting-and-identifying-row-goals):
> To summarize briefly: The row goal feature allows the optimizer to generate an execution plan (or part(s) of an execution plan) with the aim of returning a certain number of rows quickly. This is in contrast to the normal behaviour (without a row goal), which aims to find a plan optimized for the complete potential result set.
That certainly seems to be what is happening here, yet I know that the row goal optimization was disabled for this query. I am able to get a parallel query plan that executes faster if I trick SQL Server into thinking that the TOP won't limit the number of rows returned:
DECLARE @top INT = 1;
SELECT TOP (@top) Id
FROM dbo.HeapForMyTopQuestion
WHERE Id = 258
OPTION (OPTIMIZE FOR (@top = 987654321));
I don't understand why I need to use such methods. Why doesn't removing the row goal give me a parallel plan?
Code to create the test table:
DROP TABLE IF EXISTS dbo.HeapForMyTopQuestion;
CREATE TABLE dbo.HeapForMyTopQuestion (
Id INT NOT NULL
);
INSERT INTO dbo.HeapForMyTopQuestion WITH (TABLOCK)
SELECT TOP (100000000) CASE WHEN RN % 1000 = 258 THEN 1000 ELSE RN % 1000 END
FROM (
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
) q
OPTION (MAXDOP 1);
Top Answer
Paul White

In your first example, we can see the row goal and its effects on costing using undocumented trace flags 8607 and 8612 (as I describe in my article you linked to):
## With Row Goal
```
SELECT TOP (1) Id
FROM dbo.HeapForMyTopQuestion
WHERE Id = 258
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
```
~~~
PhyOp_Top NoTies
[ Card=1 Cost(RowGoal 0)= 0.00733702 ]
PhyOp_Filter
[ Card=100000 Cost(RowGoal 1)= 0.00733692 ]
PhyOp_Range TBL: dbo.HeapForMyTopQuestion(0)
[ Card=1e+08 Cost(RowGoal 1000= 0.00685692 ]
~~~
This shows the expected cardinality at each operator, and the total subtree cost. Both Filter and Range scan are affected by the row goal. The Filter expects to produce 1 row, and the Range scan expects to produce 1000 rows. In other words, the optimizer expects to need to read 1000 rows from the table before the first row passes the filter, giving the desired 1 row at the Top.
## Without Row Goal
Adding a hint to disable the row goal we see:
```
SELECT TOP (1) Id
FROM dbo.HeapForMyTopQuestion
WHERE Id = 258
--AND (SELECT 1) = 1
OPTION (USE HINT('DISABLE_OPTIMIZER_ROWGOAL'),
QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
```
~~~
PhyOp_Top NoTies
[ Card=1 Cost(RowGoal 0= 0.00733702 ]
PhyOp_Filter
[ Card=100000 Cost(RowGoal 0= 405.743 ]
PhyOp_Range TBL: dbo.HeapForMyTopQuestion(0)
[ Card=1e+08 Cost(RowGoal 0= 357.743 ]
~~~
With the row goal disabled, the Range scan expects to produce all 100 million (1e8) rows at a cost of 357.743. The Filter expects to produce 100,000 rows with a total subtree cost (including the scan) of 405.743.
### The important bit
The Top operator does not have a row goal (`RowGoal 0`). It is asked to compute the total cost of returning the first row it receives from its subtree. That cost is estimated at **0.00733702**.
This cost reflects the fact that returning one row (in no particular order) from a subtree does not require consuming all rows from that subtree. This cost is a direct consequence of the way Top works. It is not a row goal *per se*, but it does use similar reasoning.
As far as costs shown in the user-visible execution plan are concerned: The costs shown in the internal trees shown above are total subtree costs. To avoid inconsistency, child total subtree costs cannot exceed that of its parent.
The 0.00733702 subtree cost at the Top operator therefore **acts as a cap**. The entire 0.00733702 cost is assigned to the Scan, and the remaining operators (including the Top) have zero cost. If you show the Filter as a separate operator using TF 9130, you will see it has zero estimated cost as well.
Getting a parallel plan requires:
* The cost of the best serial plan at the end of the serial *search1* stage must exceed the cost threshold for parallelism.
* The tree at the end of serial *search1* must meet the entry conditions for parallel *search1*.
* The cost of the best parallel plan must be lower than the earlier best serial plan found.
Note the costs given in this answer are as reproduced on my local SQL Server 2019 CU4 instance with `FULLSCAN` statistics on the `Id` column. The screenshots in the question were likely based on auto-generated sampled statistics.
## Summary
A row goal affects the costing of child operators only. The point is to adapt the optimizer's usual costing such that the *subtree* is optimized to produce the number of rows required at the row goal, rather than the total potential result set.
A Top operator is one way to introduce a row goal. It will affect the chosen shape of operators below it, but that doesn't change the way the Top operator itself is costed. Every operator has a different costing formula with component costs for the first row and subsequent rows (including the effect of any rewinds and rebinds at that point in the plan).
The cost of a Top(n) is likely to be low in most circumstances when *n* is small. The top-down costing of completed plans means this can cap subtree operator costs as displayed to the end user.