i-one

There are a lot of nuances around handling `NULL`-s in databases[^1]. It is difficult to recall each of them even. This post is about query optimizer behavior in regard to `IS NULL` and `IS NOT NULL` comparisons over non-nullable columns, which are not removed where doing it is semantically safe, leading to unsatisfactory execution plan shape and performance.
The examples used were prepared on the SQL Server 2019 (RTM-CU12) instance. For an earlier version, adjust appropriately where necessary. Demonstrated effects are reproducible down to SQL Server 2008 R2 at least.
## **Intro**
Let's start with the simple thing, the one that you have been aware of likely. Consider the following query
```sql
DECLARE @data TABLE([C] int NOT NULL, [C2] int NULL);
SELECT [C], [C2]
FROM @data
WHERE [C] IS NOT NULL AND [C2] IS NOT NULL;
```
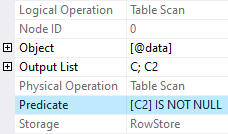
Its execution plan is extremely simple and contains Table Scan operation only

Column `[C]` in the `@data` table does not allow `NULL` values, and so it is reasonable to expect that query optimizer should be smart enough to ignore `[C] IS NOT NULL` part of the `WHERE` predicate. Indeed it is, only `[C2] IS NOT NULL` part is included in the Predicate property of the Table Scan operation
Okay. Now, if we add `RECOMPILE` hint to the query
```sql
SELECT [C], [C2]
FROM @data
WHERE [C] IS NOT NULL AND [C2] IS NOT NULL
OPTION (RECOMPILE);
```
does it change anything (aside from the compiled plan caching aspect)?
### Yes and No
Whether the `RECOMPILE` hint is specified or not, there is no difference in the execution plan produced for the subject query. But there is the difference in _how_ removal of the unnecessary part of the `WHERE` predicate happens.
#### Without RECOMPILE
When the `RECOMPILE` hint is not used, the logical tree of the query passed to the optimizer input still contains full predicate (including `[C] IS NOT NULL` part), which is reduced then during _simplification_ stage of the optimization process. Simplification includes _predicate normalization_ rules (`SelPredNorm`, `JoinPredNorm`) that are responsible, among other things, for getting rid of redundancies of such sort.
If we turn predicate normalization off for our query
```sql
SELECT [C], [C2]
FROM @data
WHERE [C] IS NOT NULL AND [C2] IS NOT NULL
OPTION (QUERYRULEOFF SelPredNorm);
```
we get full predicate in the query execution plan
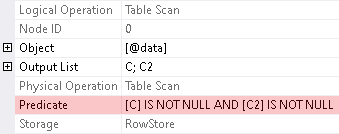
At this point we need to make some differentiation. Comparison of the non-nullable column to `NULL`, which resides in a `WHERE` predicate and is semantically redundant, can be:
- simple redundancy --- means that a part of (or possibly entire) predicate is unnecessary and can be removed safely. Following are some examples for our case
- `[C] IS NOT NULL AND [C2] IS NOT NULL` (the present one) can be reduced to `[C2] IS NOT NULL`,
- `[C] IS NULL OR [C2] IS NOT NULL` can also be reduced to `[C2] IS NOT NULL`,
- `[C] IS NOT NULL` and `[C] IS NOT NULL OR [C2] IS NOT NULL` can be reduced to `1 = 1` (_True_ internally),
- redundancy implying _contradiction_ --- means that entire predicate is equivalent to `1 = 0` (_False_ internally), and therefore no rows satisfy it. The examples for our case are `[C] IS NULL` or `[C] IS NULL AND [C2] IS NOT NULL`.
Former are subject to predicate normalization (and being reduced to True are removed afterwards), but the latter are not (they may in the join's `ON` though).
Contradiction handling is way different. Optimizer does not bother itself to reduce contradicting predicate to False here. Instead, when contradiction is detected, corresponding logical group is just flagged as _empty_. This flag can propagate in the logical tree towards the root (such as, if one side of an inner join is empty, entire join is empty too). Empty logical groups are processed then by _simplify empty_ rule family (`SelectOnEmpty`, `IJOnEmpty`, `ApplyOnEmpty` and the like). When a rule appropriate to the case sees that logical group is empty, it either replaces it by empty dataset or removes it (e.g. empty side of an outer join).
Detection of contradictions is separated from their processing. Detection logic is available in all compilation stages where logical tree makes sense, not just simplification. For the variation of our query with contradicting predicate, detection happens quite early in the compilation process, shortly after logical tree is created (well before any appreciable optimization begins). In a more complex cases it may not happen until logical tree is rearranged at a later stage. Contradiction detection mechanism is not limited to predicates only, `TOP (0)` is handled similarly, for instance. Processing of contradictions happens during simplification typically, but may occur during logical alternatives exploration as well.
These and some other stuff allow optimizer to take care of redundancies that may originate, for example, from generated queries or schema changes (which are not necessarily reflected in associated queries immediately).
#### With RECOMPILE
When the `RECOMPILE` hint is used, the logical tree of the query passed to the optimizer input does not contain `[C] IS NOT NULL` predicate part in advance. In this case, removal of the unnecessary part is the result of _constant folding_[^2].
Remember we got full predicate in the execution plan with the `SelPredNorm` turned off? With the `RECOMPILE` added
```sql
SELECT [C], [C2]
FROM @data
WHERE [C] IS NOT NULL AND [C2] IS NOT NULL
OPTION (QUERYRULEOFF SelPredNorm, RECOMPILE);
```
we get reduced predicate despite disabled predicate normalization

Presence of `QUERYRULEOFF SelPredNorm` has no effect here, because of predicate has been folded before the start of simplification.
Folding of comparisons to `NULL` has some varieties. Things like
- `[ColumnA] + [ColumnB] > NULL` --- where it does not matter what is on the other side of the comparison to `NULL`, due to semantics of null-rejecting comparisons (these include `<`, `=`, `<=`, `>`, `!=`, `>=` when `ANSI_NULLS` is `ON`),
- or `NULL IS NOT NULL`, or `CAST(1 + 2 AS bigint) IS NULL` --- where a literal constant or an expression made up of literal constants and deterministic built-in functions is compared to `NULL` by means of null-aware comparison (`IS NOT`, `IS`),
if they come from a query text, fold very early in the compilation process (during algebrization, when logical tree of the query does not even exist yet) and do not require `RECOMPILE` to be specified.
Folding of things like `[Column] IS NULL` or `[Column] IS NOT NULL`, by the contrast, does require `RECOMPILE` hint to be specified and happens at a later compilation stage (after logical tree is created). The need of the `RECOMILE` hint is the intentionally programmed behavior. This logic is implemented in the `sqllang!CScaOp_Comp::PexprFold` routine. I'm at a loss in regard to the exact reasoning behind this behavior. If you occasionally have an idea, write a comment.
Speaking more generally, folding activity is spread across the compilation process, there is no single point where it happens. There is some folding performed at the early compilation stages. Later, as logical tree is rearranged or logical alternatives generated, some folding activity may happen as well.
For the contradicting variation of our query there is not much difference between when `RECOMPILE` is specified and when it is not. The main difference is that predicate is reduced to False really (which was not the case without hint) that makes contradiction a little more obvious to the optimizer. After that, contradiction is handled in the same way as without recompilation hint.
The might of folding is that it can remove redundant comparisons to `NULL` in any part of the query (`SELECT`, `WHERE`, `GROUP BY`, `ORDER BY`, etc.). Simplification facilities are much more restricted in this sense. It is not unexpected, because of folding is aimed to reducing _expressions_, whereas simplification is aimed to preparation for later optimization stages and reducing redundancies in the _query structure_. But when it comes to the removal of unnecessary `IS NULL` and `IS NOT NULL` comparisons over non-nullable columns in a `WHERE` and a join's `ON` predicates --- situation is the opposite rather, because of one of the requirements for their folding possibility is that `RECOMPILE` hint should be specified for the query, which usually is the exceptional measure. For this reason, in majority of cases, removal of such redundancies is the result of simplification.
### Based on Comparison
Built-in functions `COALESCE`, `IIF`, `CHOOSE`, `NULLIF`, as is the `CASE` expression, are based on the comparison functionality. Side effect of this dependence is that their folding conditions conform to that of the comparison operation.
The next query uses `COALESCE`, `IIF` and `CASE` to express the same thing in three different ways
```sql
SELECT
COALESCE([C], 0),
IIF([C] IS NOT NULL, [C], 0),
CASE
WHEN [C] IS NOT NULL THEN [C]
ELSE 0
END
FROM @data;
```
(`CHOOSE` and `NULLIF` are missing from the example, because of they are based on the use of equality comparison, which is not very interesting for us).
This is the execution plan of the query
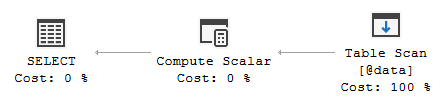
Those three expressions are represented in the Compute Scalar properties as
```none
[Expr1003] = Scalar Operator(CASE WHEN [C] IS NOT NULL THEN [C] ELSE (0) END)
[Expr1004] = Scalar Operator(CASE WHEN [C] IS NOT NULL THEN [C] ELSE (0) END)
[Expr1005] = Scalar Operator(CASE WHEN [C] IS NOT NULL THEN [C] ELSE (0) END)
```
... annoying redundancy. Compare it to the use of the `ISNULL` function
```sql
SELECT ISNULL([C], 0)
FROM @data;
```
which folds to the simple column reference
```none
[Expr1003] = Scalar Operator([C])
```
It looks like an unfortunate omission, when you encounter it, that `ISNULL` over non-nullable column is foldable and `COALESCE` is not. This is not an omission though. As we know, `COALESCE`, `IIF`, and `CASE` are comparison dependent. And `IS NOT NULL` comparison over a column requires `RECOMPILE` hint for folding (`ISNULL` is the separate intrinsic function and does not have this dependence).
With the `RECOMPILE` added to the query (which is kind of excessive for this)
```sql
SELECT
COALESCE([C], 0),
IIF([C] IS NOT NULL, [C], 0),
CASE
WHEN [C] IS NOT NULL THEN [C]
ELSE 0
END
FROM @data
OPTION (RECOMPILE);
```
all three expressions fold
```none
[Expr1003] = Scalar Operator([C])
[Expr1004] = Scalar Operator([C])
[Expr1005] = Scalar Operator([C])
```
## **Nullability Problem**
An important requirement has not been mentioned explicitly yet, one that is essential for the successful removal of unnecessary `IS NULL` and `IS NOT NULL` comparisons over a column. Optimizer must know that the column is non-nullable. It sounds super-evident probably. But this is **not the same** as having `NOT NULL` in the declaration of a table column. Let's proceed with some examples that illustrate meaning of this statement hopefully better.
### Folding Problem
Following query is semantically equivalent modification of the very first query (with identical execution plan)
```sql
SELECT [C], [C2]
FROM @data
CROSS APPLY (
SELECT 1 AS [Take]
WHERE [C] IS NOT NULL AND [C2] IS NOT NULL
) ca;
```
Similarly to the initial query, removal of the unnecessary part of the `WHERE` predicate inside the `CROSS APPLY` happens during simplification. And similarly to what we have seen before, we may expect that with the `RECOMPILE` hint added, removal will be done by means of constant folding. This does not happen however!
Even with the `RECOMPILE` hint, folding does not happen for this query, because of at the moment of folding optimizer is not able to properly derive nullability of the column `[C]` inside the `CROSS APPLY`. Only when the logical tree of the query is rearranged during simplification the optimizer is able to do it. After that, predicate normalization gets into action and predicate gets reduced. We can prove it by disabling `SelPredNorm` rule
```sql
SELECT [C], [C2]
FROM @data
CROSS APPLY (
SELECT 1 AS [Take]
WHERE [C] IS NOT NULL AND [C2] IS NOT NULL
) ca
OPTION (QUERYRULEOFF SelPredNorm, RECOMPILE);
```
Earlier we got reduced predicate in the execution plan with the `RECOMPILE` specified, regardless of the use of `QUERYRULEOFF SelPredNorm` hint. In this case we get full predicate

(because of folding fails, and predicate normalization is disabled explicitly).
Everything that depends on comparison
```sql
SELECT
COALESCE([C], 0), -- Expr1004: here optimizer knows that column C is non-nullable
ca.[Same]
FROM @data
CROSS APPLY (
SELECT COALESCE([C], 0) -- Expr1003: but here it is not
) ca([Same])
OPTION (RECOMPILE);
```
is prone to folding quirks
```none
[Expr1003] = Scalar Operator(CASE WHEN [C] IS NOT NULL THEN [C] ELSE (0) END)
[Expr1004] = Scalar Operator([C])
```
The same column can be nullable and non-nullable in the different parts of a query. Isn't it odd?
Remember that `ISNULL` can fold without the `RECOMPILE` hint? Nevertheless, proper nullability information is important even for the `ISNULL` function
```sql
SELECT ca.[C]
FROM @data
CROSS APPLY (
SELECT ISNULL([C], 0)
) ca([C]);
```
so it may not fold either
```none
[Expr1003] = Scalar Operator(isnull([C],(0)))
```
### Simplification Problem
Proper nullability information is essential for the predicate normalization and contradiction handling, without having it these mechanisms may fail as well.
Consider the following inline table-valued function
```sql
CREATE FUNCTION [RoleRequests]
(
@roleId int
)
RETURNS TABLE
AS RETURN
SELECT rq.[Id], rq.[StageId]
FROM [Requests] rq
WHERE @roleId IS NULL
OR @roleId IS NOT NULL AND EXISTS (
SELECT 1
FROM [RoleStages] rs
WHERE rs.[RoleId] = @roleId AND rs.[StageId] = rq.[StageId]
);
```
Its purpose is to return data from the `Requests` table that a role (passed in the `@roleId` argument) is allowed to see. Each request has a `StageId` attribute, and the `RoleStages` table holds information about stages that a role is allowed to see. If `NULL` argument is passed to the function, it returns all data available in the `Requests` table. You may find entire script that includes creation of tables and sample data at the end of the post.
The next query uses this function to count requests available to a role
```sql
DECLARE @roleId int = 2;
SELECT COUNT_BIG(*)
FROM [RoleRequests](@roleId)
OPTION (MAXDOP 1, USE HINT('DISALLOW_BATCH_MODE'));
```
This is the execution plan
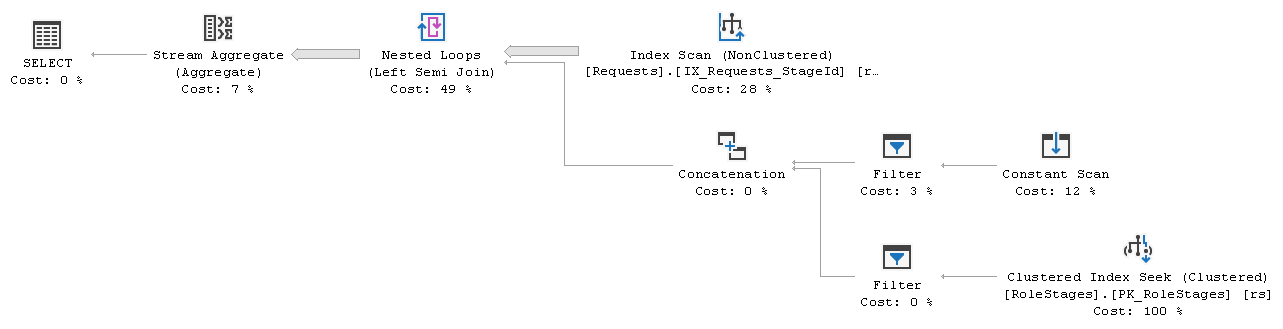
We are not interested in its performance, just overall plan shape. There is the Stream Aggregate performing `COUNT_BIG` over rows coming from the Nested Loops (Left Semi Join). Beyond the semi-join, as its outer (top) input, there is the Index Scan over the `IX_Requests_StageId` index. And as its inner (bottom) input, there is the Concatenation of the Constant Scan and the Clustered Index Seek over the `PK_RoleStages` index, each beyond its own Filter.
Filter to the left of the Constant Scan has Startup Expression defined as `@roleId IS NULL`, and Filter to the left of the Clustered Index Seek has Startup Expression defined as `@roleId IS NOT NULL`
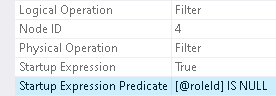 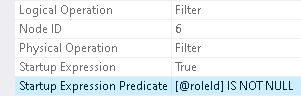
These two predicates cannot evaluate to True at the same time. And so, depending on the argument, either the Constant Scan is executed or the Clustered Index Seek is executed, but not both. Thus, either all rows from the `Requests` table are sent for aggregation (because of Constant Scan always returns one row) or those only which have match in the `RoleStages` table for the given `@roleId` (as `@roleId` is the part of seek predicate of the Clustered Index Seek).
As the next step, we are provided with a set of roles in the `#Roles` table
```
CREATE TABLE [#Roles] ([Id] int NOT NULL PRIMARY KEY);
```
The requirement is to count number of distinct requests that roles from the provided set are allowed to see. Here is the query doing it with the function we have
```sql
SELECT COUNT_BIG(DISTINCT rq.[Id])
FROM [#Roles] r
CROSS APPLY [RoleRequests](r.[Id]) rq
OPTION (MAXDOP 1, USE HINT('DISALLOW_BATCH_MODE'));
```
(this and further queries use `MAXDOP 1` and `DISALLOW_BATCH_MODE` hints for more compact execution plans and shorter explanation).
The execution plan shape is similar to the previous one
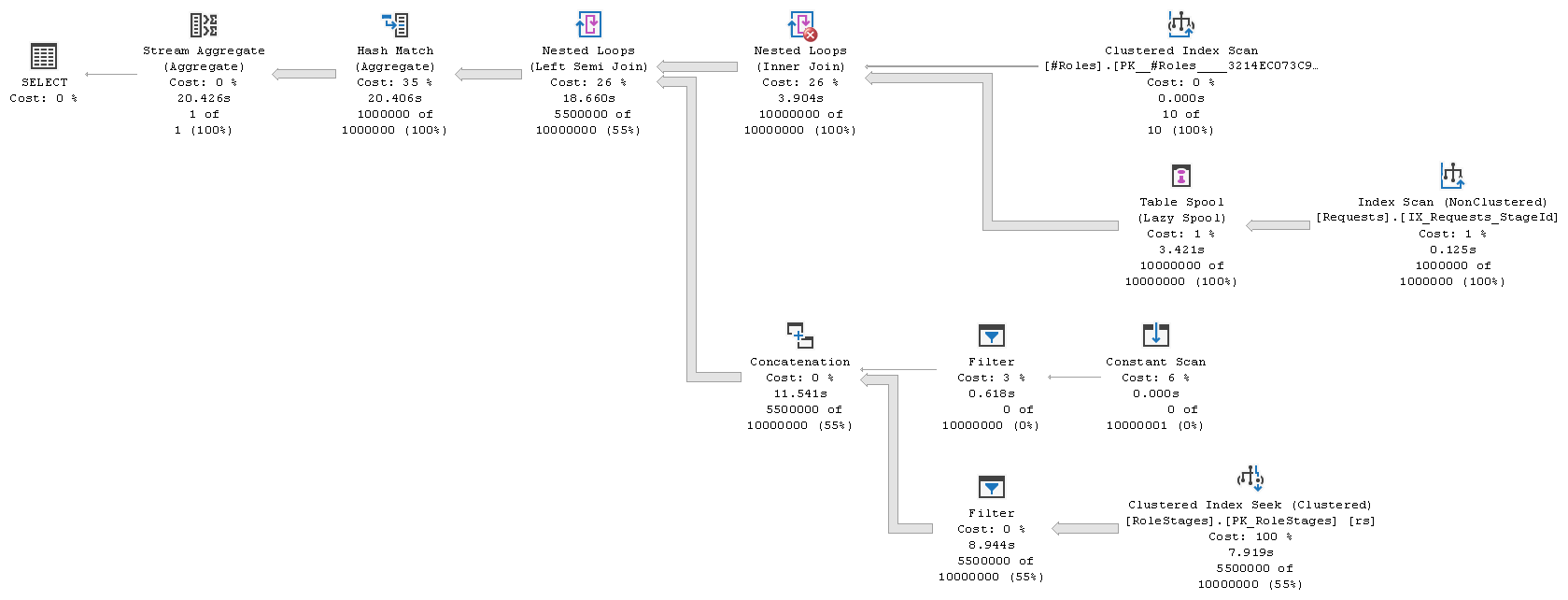
with some differences though. There is the additional Hash Match (Aggregate) operation that performs `DISTINCT`. The other difference is the outer (top) input of the semi-join. This time it is cross join of the `#Roles` table and the `IX_Requests_StageId` index. The Table Spool here is the _performance spool_[^3] and is introduced for the cost reason. Estimated cost of this plan is **160.485** units on my system.
Watchful reader might have a question at this point. Wait a minute! What Filters do here?
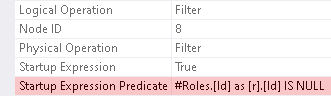 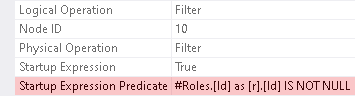
The `Id` column is non-nullable in the `#Roles` table and in this part of the plan it is an outer reference, so it can never be `NULL`. Filter to the left of the Constant Scan has contradicting predicate, which means that entire branch (and Concatenation hence) can be removed. And Filter to the left of Clustered Index Seek is simply redundant. So, at the very least we should see Clustered Index Seek connected to the inner (bottom) input of the semi-join directly. Optimizer was not able to do all that, because of nullability of the compared column was not derived properly.
Without actual plan included, average execution time for this plan is **15043 msec** for me. The Table Spool builds its working table with the same two columns as its source index, and actually hurts performance here rather than raises it. With the `NO_PERFORMANCE_SPOOL` hint added, average execution time decreases to **12350 msec**. Without any hints specified, optimizer generates Row execution mode parallel plan with similar shape, which runs to completion for **7446 msec** on the average. If `NO_PERFORMANCE_SPOOL` is the only hint used, execution time drops to **5521 msec**. It can be improved even further, but we are not pursuing ultimate performance here.
Event at its best variation (parallel, without spool) this plan shape is not very efficient. Unnecessary Concatenation and two Filters decrease performance of course, but not dramatically. The Constant Scan is unnecessary too, but it is not executed. Much of the inefficiency stems from the plan shape itself. We have multiple scans of data of the relatively large `Requests` table here and ten million singleton seeks over `PK_RoleStages` index, one per each row of the cross join of `#Roles` and `Requests` tables.
Let's rewrite previous query from scratch, without using the function. One of the possible ways to do it, so that it fulfills the requirement, is
```sql
SELECT COUNT_BIG(DISTINCT rq.[Id])
FROM [#Roles] r
JOIN [RoleStages] rs ON rs.[RoleId] = r.[Id]
JOIN [Requests] rq ON rq.[StageId] = rs.[StageId]
OPTION (MAXDOP 1, USE HINT('DISALLOW_BATCH_MODE'));
```
This is the execution plan
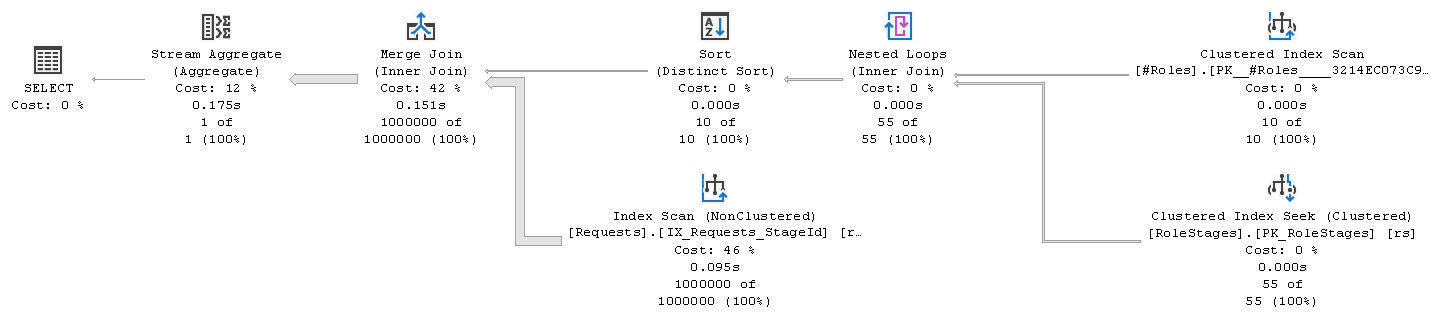
Absence of the unnecessary comparisons allowed optimizer to find better plan. It came up with the shape that joins list of distinct `StageId` values (obtained from join of the `#Roles` and the `RoleStages` tables) and the `Requests` table, which is scanned once. Estimated cost of this plan is **5.21275** units and its average execution time is just **102 msec**! It is possible to further improve it by engaging parallelism and Batch mode execution.
You might get an impression that presence of unnecessary comparisons to `NULL` in the query body prevents optimizer from being able to find better plan shape. This is not exactly how it should be formulated though.
Let's manually inline our `RoleRequests` function into the query. This is how it looks
```sql
SELECT COUNT_BIG(DISTINCT rq.[Id])
FROM [#Roles] r
CROSS APPLY (
SELECT rq.[Id], rq.[StageId]
FROM [Requests] rq
WHERE r.[Id] IS NULL
OR r.[Id] IS NOT NULL AND EXISTS (
SELECT 1
FROM [RoleStages] rs
WHERE rs.[RoleId] = r.[Id] AND rs.[StageId] = rq.[StageId]
)
) rq
OPTION (MAXDOP 1, USE HINT('DISALLOW_BATCH_MODE'));
```
This query has the same execution plan as we got earlier using the function
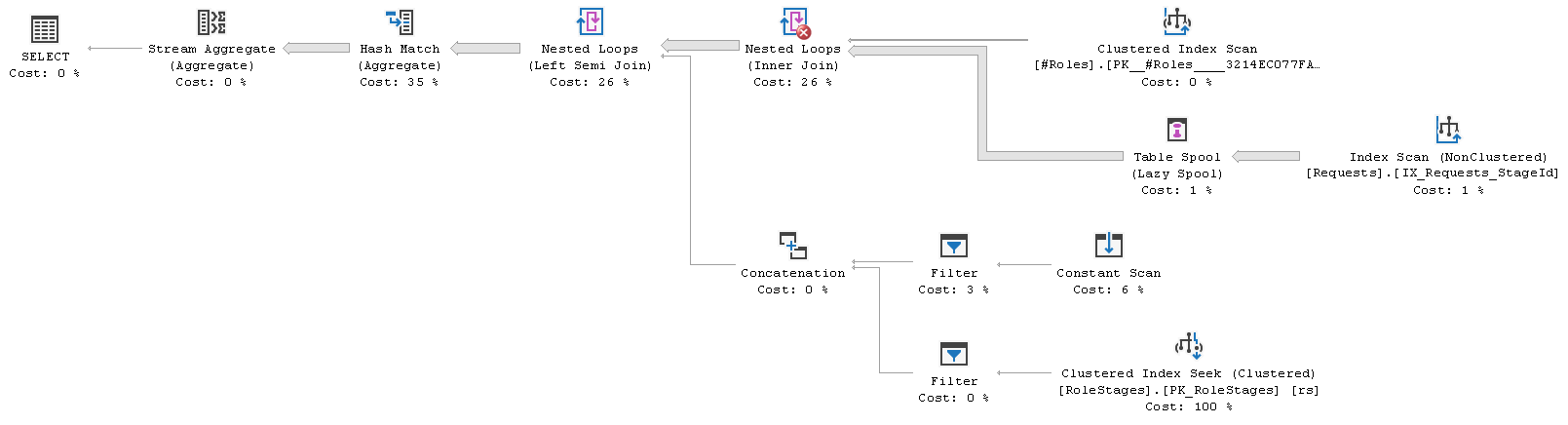
As the next step, let's move `WHERE` from inside the `CROSS APPLY` to the outer scope
```sql
SELECT COUNT_BIG(DISTINCT rq.[Id])
FROM [#Roles] r
CROSS APPLY (
SELECT rq.[Id], rq.[StageId]
FROM [Requests] rq
) rq
WHERE r.[Id] IS NULL
OR r.[Id] IS NOT NULL AND EXISTS (
SELECT 1
FROM [RoleStages] rs
WHERE rs.[RoleId] = r.[Id] AND rs.[StageId] = rq.[StageId]
)
OPTION (MAXDOP 1, USE HINT('DISALLOW_BATCH_MODE'));
```
After this rewrite, the `CROSS APPLY` becomes cross join effectively, and so we can rewrite query in a bit shorter form
```sql
SELECT COUNT_BIG(DISTINCT rq.[Id])
FROM [#Roles] r
CROSS JOIN [Requests] rq
WHERE r.[Id] IS NULL
OR r.[Id] IS NOT NULL AND EXISTS (
SELECT 1
FROM [RoleStages] rs
WHERE rs.[RoleId] = r.[Id] AND rs.[StageId] = rq.[StageId]
)
OPTION (MAXDOP 1, USE HINT('DISALLOW_BATCH_MODE'));
```
This is the execution plan generated for this and previous rewrites

Its shape is exactly the same as we got for the "from scratch" rewrite little earlier. Once the predicate was moved to a position convenient to evaluate `r.[Id]` nullability, optimizer was able to do its job better.
The problem we have here has broader scope actually. Nullability is just one particular type of a constraint. Equally we could have, for example, `CHECK ([Id] != 0)` defined in the `#Roles` table, and
```sql
...
WHERE r.[Id] = 0
OR r.[Id] != 0 AND EXISTS (
...
```
in the function body. A more complex constraint and corresponding predicates could cause similar problem.
One additional entertaining thing, as the ending of this section. Function `RoleRequests` can be rewritten to use `LEFT JOIN` instead of `EXISTS`, see `RoleRequestsLJ` modification in the setup scripts. With this function used
```sql
SELECT COUNT_BIG(DISTINCT rq.[Id])
FROM [#Roles] r
CROSS APPLY [RoleRequestsLJ](r.[Id]) rq
OPTION (MAXDOP 1, USE HINT('DISALLOW_BATCH_MODE'));
```
execution plan generated for the query contains Filter operation
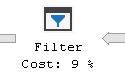
that has startup predicate defined as

It is funny to see it, because of these two opposite conditions combined with `OR` always evaluate to True, irrespective of the nullability of the `r.[Id]` column!
## **Final Words**
Optimizer has a good diversity of mechanisms to deal with various redundancies. Sometimes it is not as good as we want it to be unfortunately.
It is not fair probably to claim about folding, because of folding is mainly oriented to expressions based on literal constants. Documentation is explicit on this matter --- expressions that depend on the value of a column are non-foldable. And so, some "positive" inconsistencies to this restriction, that we have seen here, are more of an extra functionality. And what looks like a problem is the normal behavior likely.
Simplification problem is more real. May be it exists because of it is not that simple to fix it as it looks from the examples we have here. Bad thing is that source of the problem may not be evident instantly from the execution plan. Knowledge of the schema is important. Suspicious Filters are worth paying attention, but seeing unnecessary predicates in the join nodes is possible as well. General advise is probably to write queries in such a way that predicates are at the same scope as their source tables, where possible. Correlated subqueries are sensitive to the issue particularly. Rewrite may be necessary.
---
### Auxiliary Script
```sql
-- Setup Schema
CREATE TABLE [Requests]
(
[Id] int NOT NULL,
[StageId] int NOT NULL,
CONSTRAINT [PK_Requests] PRIMARY KEY ([Id]),
INDEX [IX_Requests_StageId] ([StageId])
);
GO
CREATE TABLE [RoleStages]
(
[RoleId] int NOT NULL,
[StageId] int NOT NULL,
CONSTRAINT [PK_RoleStages] PRIMARY KEY ([RoleId], [StageId])
);
GO
CREATE FUNCTION [RoleRequests]
(
@roleId int
)
RETURNS TABLE
AS RETURN
SELECT rq.[Id], rq.[StageId]
FROM [Requests] rq
WHERE @roleId IS NULL
OR @roleId IS NOT NULL AND EXISTS (
SELECT 1
FROM [RoleStages] rs
WHERE rs.[RoleId] = @roleId AND rs.[StageId] = rq.[StageId]
);
GO
CREATE FUNCTION [RoleRequestsLJ]
(
@roleId int
)
RETURNS TABLE
AS RETURN
SELECT rq.[Id], rq.[StageId]
FROM [Requests] rq
LEFT JOIN [RoleStages] rs ON rs.[RoleId] = @roleId AND rs.[StageId] = rq.[StageId]
WHERE @roleId IS NULL
OR @roleId IS NOT NULL AND rs.[StageId] IS NOT NULL;
GO
CREATE TABLE [#Roles] ([Id] int NOT NULL PRIMARY KEY);
GO
-- Make Data
CREATE TABLE [Numbers] ([N] int, CONSTRAINT [PK_Numbers] PRIMARY KEY CLUSTERED ([N]));
GO
INSERT INTO [Numbers] WITH (TABLOCK) ([N])
SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM sys.all_columns a, sys.all_columns b;
GO
INSERT INTO [Requests] WITH (TABLOCK) ([Id], [StageId])
SELECT [N], [N] % 10 + 1
FROM [Numbers]
WHERE [N] BETWEEN 1 AND 1000000;
GO
INSERT INTO [RoleStages] WITH (TABLOCK) ([RoleId], [StageId])
SELECT r.[N], s.[N]
FROM [Numbers] r
JOIN [Numbers] s ON s.[N] BETWEEN 1 AND (r.[N] - 1) % 10 + 1
WHERE r.[N] BETWEEN 1 AND 10;
GO
INSERT INTO [#Roles] WITH (TABLOCK) ([Id])
VALUES (1), (2), (3), (4), (5), (6), (7), (8), (9), (10);
GO
UPDATE STATISTICS [Requests] WITH FULLSCAN;
UPDATE STATISTICS [RoleStages] WITH FULLSCAN;
GO
```
[^1]: [NULL complexities – Part 1](https://sqlperformance.com/2019/12/t-sql-queries/null-complexities-part-1), [Part 2](https://sqlperformance.com/2020/01/t-sql-queries/null-complexities-part-2), [Part 3](https://sqlperformance.com/2020/02/t-sql-queries/null-complexities-part-3-missing-standard-features-and-t-sql-alternatives), [Part 4](https://sqlperformance.com/2020/03/t-sql-queries/null-complexities-part-4-missing-standard-unique-constraint) by Itzik Ben-Gan
[^2]: [Query Processing Architecture Guide - SQL Statement Processing - Constant Folding and Expression Evaluation](https://docs.microsoft.com/en-us/sql/relational-databases/query-processing-architecture-guide#ConstantFolding)
[^3]: [Nested Loops Joins and Performance Spools](https://sqlperformance.com/2019/09/sql-performance/nested-loops-joins-performance-spools) by Paul White