i-one

As shown in my [Update from PIVOT][1] post, use of the `PIVOT` syntax sometimes demonstrates noticeable difference in comparison to use of the standard aggregation of `CASE` expressions. And the difference can even cause drop of performance. In this post I want to show the other side of the `PIVOT`'s dissimilarity, when `PIVOT` can suddenly perform better than standard aggregation.
## **Setup**
As usual, we will need some tables and data to play with. The following table will store data being pivoted
```sql
CREATE TABLE [Data]
(
[Id] int IDENTITY(1,1) NOT NULL,
[ItemId] int NOT NULL,
[Quarter] tinyint NOT NULL,
[Value] decimal(12,2) NOT NULL,
CONSTRAINT [PK_Data] PRIMARY KEY CLUSTERED ([Id]),
CONSTRAINT [CK_Data_Quarter] CHECK ([Quarter] BETWEEN 1 AND 4)
);
GO
CREATE UNIQUE INDEX [UX_Data] ON [Data] ([Quarter], [ItemId]);
GO
```
It will be loaded with four million rows (one million items, each in four quarters)
```sql
INSERT INTO [Data] WITH (TABLOCK) ([ItemId], [Quarter], [Value])
SELECT itm.[N], q.[N], 100.0 * q.[N]
FROM [Numbers] itm
CROSS JOIN [Numbers] q
WHERE itm.[N] BETWEEN 1 AND 1000000
AND q.[N] BETWEEN 1 AND 4;
GO
UPDATE STATISTICS [Data] WITH FULLSCAN;
GO
```
(if you don't have numbers table, you may take script for its creation at the end of the [previous][1] post dedicated to `PIVOT`).
## **Requirement**
We are provided with a set of (a few) item identifiers in the `[#Items]` table
```sql
CREATE TABLE [#Items] ([Id] int NOT NULL PRIMARY KEY);
INSERT INTO [#Items] WITH (TABLOCK) ([Id])
VALUES (1), (10), (100), (1000), (10000), (100000), (1000000), (10000000);
```
The requirement is to return values for these items pivoted by quarters, taking into account that row should be returned for each item, even if there is no data for a particular item in the `[Data]` table.
Let’s perform the task using standard aggregation first and then using `PIVOT` syntax, and see how they differ.
## **Standard Aggregation**
In the case of standard aggregation, the following query can be used to satisfy the requirement
```sql
SELECT
it.[Id],
[Q1] = MAX(CASE itd.[Quarter] WHEN 1 THEN itd.[Value] END),
[Q2] = MAX(CASE itd.[Quarter] WHEN 2 THEN itd.[Value] END),
[Q3] = MAX(CASE itd.[Quarter] WHEN 3 THEN itd.[Value] END),
[Q4] = MAX(CASE itd.[Quarter] WHEN 4 THEN itd.[Value] END)
FROM [#Items] it
LEFT JOIN [Data] itd ON itd.[ItemId] = it.[Id]
GROUP BY it.[Id]
OPTION (MAXDOP 1);
```
(option `MAXDOP 1` is added for simplicity).
This is the execution plan of the query

Estimated cost of the generated plan is **14.3259** units on my system (an instance of SQL Server 2019). Good thing here is that query optimizer was able to utilize Batch mode execution on rowstore
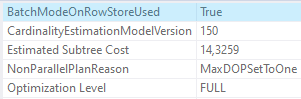
The other good thing is that Hash Match (Left Outer Join) node has `BitmapCreator` attribute set
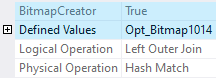
which means that it takes advantage of Batch mode bitmaps[^1]. Clustered Index Scan on the probe-side of Hash Match features corresponding `PROBE` predicate

that did excellent job to reduce amount of rows fed to join from the `[PK_Data]` clustered index

Bad thing in this plan is that execution engine has to read **all four million rows** from the `[Data]` table, whereas rows for just a few items are needed actually.
We could get better (and lower costing) execution plan if `[Data]` table had an index on the `[ItemId]` column. There is the `[UX_Data]` index that has `[ItemId]` column as the part of index key but it is not leading column, and so this index is not helpful for the query. Execution plan has missing index warning actually
```sql
CREATE NONCLUSTERED INDEX <Name of Missing Index> ON [Data] ([ItemId]) INCLUDE ([Quarter], [Value]);
```
but we are not going to follow optimizer's suggestion, because of we need to look how `PIVOT` will perform.
With the existing indexes in place, these are the run-time statistics for the query
```none
Table 'Data'. Scan count 1, logical reads 13406, physical reads 0, ...
Table '#Items'. Scan count 1, logical reads 2, physical reads 0, ...
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, ...
SQL Server Execution Times:
CPU time = 194 ms, elapsed time = 195 ms.
```
Execution time is not so bad, thanks to all those optimizations.
## **PIVOT Syntax**
Following is the equivalent query that uses `PIVOT` syntax
```sql
WITH d AS (
SELECT it.[Id], itd.[Quarter], itd.[Value]
FROM #Items it
LEFT JOIN [Data] itd ON itd.[ItemId] = it.[Id]
)
SELECT
[Id],
[1] AS [Q1],
[2] AS [Q2],
[3] AS [Q3],
[4] AS [Q4]
FROM d
PIVOT (MAX([Value]) FOR [Quarter] IN ([1], [2], [3], [4])) pvt
OPTION (MAXDOP 1);
```
and this is its execution plan

Estimated cost of the generated plan is just **0.118709** units and its performance is way better
```none
Table 'Data'. Scan count 32, logical reads 183, physical reads 0, ...
Table '#Items'. Scan count 1, logical reads 2, physical reads 0, ...
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
```
Much less reads over the `[Data]` table and near to instant execution time. Most interesting in this execution plan, in comparison to previous one, is that somehow query optimizer was able to utilize seek over `[UX_Data]` index on the `[Data]` table.
If we inspect properties of the Index Seek operator, we can notice that optimizer added predicates for `[Quarter]` column of the `[Data]` table that were not present in the query text. Below is the piece of `SHOWPLAN_TEXT` output (that expresses things in the most readable form seemingly)
```none
SEEK:(
[itd].[Quarter]=(1) AND [itd].[ItemId]=#Items.[Id] as [it].[Id]
OR [itd].[Quarter]=(2) AND [itd].[ItemId]=#Items.[Id] as [it].[Id]
OR [itd].[Quarter]=(3) AND [itd].[ItemId]=#Items.[Id] as [it].[Id]
OR [itd].[Quarter]=(4) AND [itd].[ItemId]=#Items.[Id] as [it].[Id]
) ORDERED FORWARD
```
This complex seek predicate can be rewritten in short as
```sql
itd.[ItemId] = it.[Id] AND itd.[Quarter] IN (1, 2, 3, 4)
```
The `[Quarter] IN (1, 2, 3, 4)` part resulted from `ExpandPivotLOJ` transformation, which is considered in addition to `ExpandPivot` transformation (usual for `PIVOT` queries) if `PIVOT` is over the `LEFT JOIN`. It expands `PIVOT` to aggregation and builds additional predicate based on the `FOR` clause of the `PIVOT`. The `RIGHT JOIN` can be appropriate as well, because of normally optimizer commutes right joins to left during simplification.
Additional predicate allowed optimizer to employ seek over `[UX_Data]` index and avoid excessive reading from the `[Data]` table

Possible point of concern in this execution plan is the Key Lookup operation. Depending on additional requirements it can be tolerated or avoided by making `[Value]` column included into `[UX_Data]` index.
### PIVOT Under-Optimization
If we add predicate `[Quarter] IN (1, 2, 3, 4)` to our standard aggregation query
```sql
SELECT
it.[Id],
[Q1] = MAX(CASE itd.[Quarter] WHEN 1 THEN itd.[Value] END),
[Q2] = MAX(CASE itd.[Quarter] WHEN 2 THEN itd.[Value] END),
[Q3] = MAX(CASE itd.[Quarter] WHEN 3 THEN itd.[Value] END),
[Q4] = MAX(CASE itd.[Quarter] WHEN 4 THEN itd.[Value] END)
FROM [#Items] it
LEFT JOIN [Data] itd ON itd.[ItemId] = it.[Id] AND itd.[Quarter] IN (1, 2, 3, 4)
GROUP BY it.[Id]
OPTION (MAXDOP 1);
```
and obtain its execution plan, we will find it similar to the one we had for `PIVOT` syntax. The `ExpandPivotLOJ` transformation is not full equivalent to this rewrite however.
In the case of standard aggregation, if we specify additional predicate as `[Quarter] IN (1, 2, 3, 4, 5)`, we will not be able to find `[Quarter] = 5` anywhere in the execution plan. During predicate normalization optimizer will detect the fact that part of the predicate contradicts `[CK_Data_Quarter]` check constraint, which only allows `[Quarter] BETWEEN 1 AND 4`, and will get rid of this contradicting part.
In the case of `PIVOT` syntax, if we specify `FOR [Quarter] IN ([1], [2], [3], [4], [5])` we will be able to see `[Quarter] = 5` among the seek predicates. Optimizer will not throw it away, because of predicate normalization happens earlier than additional predicate is created by `ExpandPivotLOJ` transformation.
In realistic scenario this under-optimization should not be point of concern probably, but it is worth noting.
## **Final Thoughts**
Query optimizer has dedicated logical operation `LogOp_Pivot` for internal representation of the `PIVOT` construct, which is expanded to aggregate operation `LogOp_GbAgg` during optimization.
On the one hand, having it this way allows applying specific optimizations, like the one that is subject of this post. Optimizer has a number of logical operations that could be expressed by means of general purpose operations (`LogOp_Join`, `LogOp_Select`, `LogOp_GbAgg`, etc.) but do exist as dedicated nonetheless. They service various internal concepts and allow consideration of limited set of transformations, thus confining search space. N-ary join (`LogOp_NAryJoin`), star join[^2] (`LogOp_StarJoin`) or pseudo-select join (`LogOp_PseudoSelectJoin`) are the examples particularly.
On the other hand, `LogOp_Pivot` is expanded quite late in the optimization pipeline, during cost-based optimization. Consequence of this late expansion is that some simplifications are not available for queries that use `PIVOT` syntax. As a result, `PIVOT` queries may demonstrate under-optimizations, like the one mentioned earlier in this post or the other one considered in the [previous][1]. There are more actually, that I would like to cover in one of the future posts.
So, here is the architectural dilemma. Late expansion makes applying specific optimizations easy, at the price of losing some useful simplifications. Early expansion makes all simplifications available, but makes detecting pivot pattern harder and carries risk of its destruction by some of the simplifications with subsequent impossibility to detect it and apply specific optimizations.
I'm a bit skeptic about the idea of `LogOp_Pivot` due to the following reasons. Appearance of the `PIVOT` syntax and all related stuff dates back to release of the SQL Server 2005. But what do we have today? The `ExpandPivotLOJ` is the **only** transformation specific for `PIVOT`. The `ExpandPivot` does not count, because of it is simple expansion. And the `SelOnPivot` (one of the many predicate pushdown facilities) does not count too, because of its existence is justified by the existence of `LogOp_Pivot` solely (no `LogOp_Pivot`, no need for `SelOnPivot`). There could be more specific optimizations (and more sense to have `LogOp_Pivot`) probably if `PIVOT` syntax were evolved. But, since appearance, it did not.
I hope that previous paragraph does not sound too dark. The point is not that `PIVOT` is bad, it is not and is just syntax after all. The point, as a whole, is to draw attention once again to the fact that `PIVOT` is not fully equivalent to `CASE`-s aggregation due to slightly different internal handling.
[^1]: [Batch Mode Bitmaps in SQL Server](https://sqlperformance.com/2019/08/sql-performance/batch-mode-bitmaps-in-sql-server) by Paul White
[^2]: [StarJoinInfo in Execution Plans](https://sqlperformance.com/2014/01/sql-plan/starjoininfo-in-execution-plans) by Paul White
[1]: https://topanswers.xyz/databases?q=953