Joe Obbish

Data prep:
DROP TABLE IF EXISTS #;
CREATE TABLE # (
ID BIGINT NOT NULL,
ID2 BIGINT NOT NULL
PRIMARY KEY (ID, ID2)
);
INSERT INTO # WITH (TABLOCK)
SELECT RN, v.v
FROM (
SELECT TOP (4000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values
CROSS JOIN master..spt_values t2
) q
CROSS JOIN (VALUES (1), (2), (3), (4), (5), (6), (7)) v(v);
I expect the following query to result in a query plan with an apply:
SELECT ca.*
FROM (
VALUES
(1, 1000),
(1001, 2000),
(2001, 3000),
(3001, 4000)
) driver( s, e)
CROSS APPLY (
SELECT ID, COUNT_BIG(*) cnt
FROM # WITH (FORCESEEK)
WHERE ID BETWEEN CAST(driver.s AS BIGINT) AND CAST(driver.e AS BIGINT)
GROUP BY ID
) ca;
Instead I get an error:
> Msg 8622, Level 16, State 1, Line 25
> Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
I don't understand why. A query plan exists that would honor the `FORCESEEK` hint. An artist's rendition:
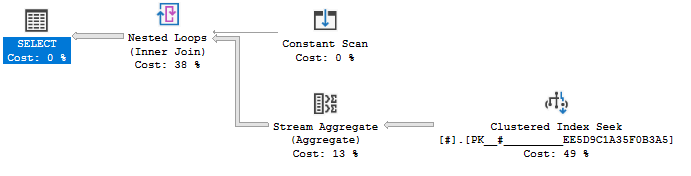
I am able to get a query plan by adding a TOP expression:
SELECT ca.*
FROM (
VALUES
(1, 1000),
(1001, 2000),
(2001, 3000),
(3001, 4000)
) driver( s, e)
CROSS APPLY (
SELECT TOP (987654321987654321) ID, COUNT_BIG(*) cnt
FROM # WITH (FORCESEEK)
WHERE ID BETWEEN CAST(driver.s AS BIGINT) AND CAST(driver.e AS BIGINT)
GROUP BY ID
) ca;
Why does the original query result in error 8622 and why does adding a TOP resolve that error?
Top Answer
Paul White

Although the query text contains an `APPLY`, the optimizer rewrites this to a regular join using the `ApplyHandler` rule early in the compilation process (during simplification). The optimizer prefers joins over applies because it has more transformations for joins[^1].
The tree at this point is essentially:
~~~
LogOp_Join
LogOp_ConstTableGet (4) Union1008, Union1009
LogOp_GbAgg OUT([#].ID, Expr1012) BY([#].ID,)
LogOp_Project
LogOp_Get TBL: #
AncOp_PrjEl Expr1012
ScaOp_AggFunc stopCountBig
ScaOp_Logical x_lopAnd
ScaOp_Comp x_cmpGe
ScaOp_Identifier [#].ID
ScaOp_Convert bigint,Null,ML=8
ScaOp_Identifier Union1008
ScaOp_Comp x_cmpLe
ScaOp_Identifier [#].ID
ScaOp_Convert bigint,Null,ML=8
ScaOp_Identifier Union1009
~~~
> Why does the original query result in error 8622?
The optimizer will generally consider transforming a join to an apply (the reverse of the prior rewrite) during cost-based optimization.
Unfortunately (*for you*), the aggregate in the tree above means the optimizer is unable to generate an apply form of the query tree at that time.
One could manually rewrite the query, moving the `GROUP BY` outside the derived table to achieve the seek, but the resulting plan may be less efficient. One possible implementation is:
<>https://dbfiddle.uk/?rdbms=sqlserver_2019&fiddle=a62a9cf9472b39323aadf649edf1fdf0&hide=1
Without an apply, an inner-side seek is logically impossible, because there is no value to seek to.
You might wonder why the optimizer doesn't use the original apply form of the query. That is unavailable to the optimizer, because rewrites before cost-based optimization are *destructive*. The original form of the query tree has been replaced, not added to a list of alternate plans.
In any case, reverting to the early form would lose any improvements made after that point, and before cost-based optimization started.
> Why does adding a TOP resolve that error?
Developers have used `TOP` in this way for years to prevent transformation from apply to join. SQL Server currently honours this intent (conscious or otherwise) by not rewriting apply to join where a top is present, even where it would be logically possible to do.
Similarly, explicitly disabling the `ApplyHandler` rule with undocumented trace flag 9114, removes the early rewrite to a join, and so allows the desired *seek* plan to be produced. The tree remains in the apply form, so the correlated value can be used to seek with.
---
By the way, if you find the `TOP` clause inconvenient, and/or the maximum value of a `bigint` difficult to remember, one can employ `ORDER BY`:
```
SELECT ca.*
FROM
(
VALUES
(CONVERT(bigint, 1), CONVERT(bigint, 1000)),
(1001, 2000),
(2001, 3000),
(3001, 4000)
) AS driver( s, e)
CROSS APPLY
(
SELECT COUNT_BIG(*) AS cnt
FROM # WITH (FORCESEEK)
WHERE #.ID BETWEEN driver.s AND driver.e
GROUP BY #.ID
ORDER BY #.ID
OFFSET 0 ROWS
) ca;
```
The plan is the same:

SQL Server adds the number 9223372036854775807 *for you*.
[^1]: For background on the difference between join and apply, see my article [Apply versus Nested Loops Join](https://www.sql.kiwi/2019/06/apply-versus-nested-loops-join.html)
Answer #2
i-one

To supplement Paul's answer, ironically, the optimizer is capable of producing apply plan for the original query, if `OUTER APPLY` is used instead of the `CROSS APPLY`
```sql
SELECT ca.*
FROM (VALUES
(1, 1000),
(1001, 2000),
(2001, 3000),
(3001, 4000)
) driver( s, e)
OUTER APPLY (
SELECT ID, COUNT_BIG(*) cnt
FROM # WITH (FORCESEEK)
WHERE ID BETWEEN CAST(driver.s AS BIGINT) AND CAST(driver.e AS BIGINT)
GROUP BY ID
) ca;
```

Obviously changing `CROSS` to `OUTER` may not be applicable. And even when we know that query semantics can tolerate such a change, it should be weighted anyway, because of optimizer behavior is different for `CROSS` and `OUTER` (this includes, for example, transformation rules availability or possibility of moving scalar expressions in the logical tree).
---
Following are the key points of the optimization path of `OUTER` modification.
The Input Tree contains `LogOp_Apply` initially
```none
*** Input Tree: ***
LogOp_Project COL: Expr1013 COL: Expr1014
LogOp_Apply (x_jtLeftOuter)
LogOp_ConstTableGet (4) COL: Union1008 COL: Union1009
...
LogOp_Project
LogOp_GbAgg OUT(QCOL: [tempdb].[dbo].[#].ID,COL: Expr1012 ,) BY(QCOL: [tempdb].[dbo].[#].ID,)
...
```
Then, during simplification, `ApplyHandler` rule transforms apply to join and promotes correlated predicate to join predicate
```none
*** Simplified Tree: ***
LogOp_LeftOuterJoin
LogOp_ConstTableGet (4) COL: Union1008 COL: Union1009
...
LogOp_Project
LogOp_GbAgg OUT(QCOL: [tempdb].[dbo].[#].ID,COL: Expr1012 ,) BY(QCOL: [tempdb].[dbo].[#].ID,)
...
ScaOp_Logical x_lopAnd
ScaOp_Comp x_cmpGe
ScaOp_Identifier QCOL: [tempdb].[dbo].[#].ID
ScaOp_Convert bigint,Null,ML=8
ScaOp_Identifier COL: Union1008
ScaOp_Comp x_cmpLe
ScaOp_Identifier QCOL: [tempdb].[dbo].[#].ID
ScaOp_Convert bigint,Null,ML=8
ScaOp_Identifier COL: Union1009
```
so, logical tree becomes equivalent to
```sql
SELECT ca.*
FROM (VALUES
(1, 1000),
(1001, 2000),
(2001, 3000),
(3001, 4000)
) driver(s, e)
LEFT JOIN (
SELECT ID, COUNT_BIG(*) cnt
FROM #
GROUP BY ID
) ca ON ca.ID BETWEEN CAST(driver.s AS BIGINT) AND CAST(driver.e AS BIGINT);
```
During cost-based optimization join is transformed back to apply by `LOJNtoApply` rule
```none
Rule Result: group=36 1 <LOJNtoApply>LogOp_Apply 27 44 (Distance = 1)
Subst:
LogOp_Apply (x_jtLeftOuter)
...
```
(this is what I call "optimization bureaucracy", like one department rejects what another approved).
Then `ApplyToNL` rule performs transformation of logical apply to physical
```none
Rule Result: group=36 3 <ApplyToNL>PhyOp_Applyx_jtLeftOuter 27 44 (Distance = 2)
Subst:
PhyOp_Apply (x_jtLeftOuter)
...
```
which becomes Nested Loops join as the part of post-optimization rewrite finally.