Martin Smith

**Setup**
CREATE TABLE T1(X INT NULL UNIQUE CLUSTERED);
CREATE TABLE T2(X INT NULL UNIQUE CLUSTERED);
INSERT INTO T1
OUTPUT INSERTED.X INTO T2
SELECT TOP 100000 NULLIF(ROW_NUMBER() OVER (ORDER BY 1/0),1)
FROM sys.all_objects o1,
sys.all_objects o2;
**Query**
WITH CTE AS
(
SELECT X FROM T1
UNION ALL
SELECT X FROM T2
)
SELECT MAX(X)
FROM CTE
**Execution Plan**
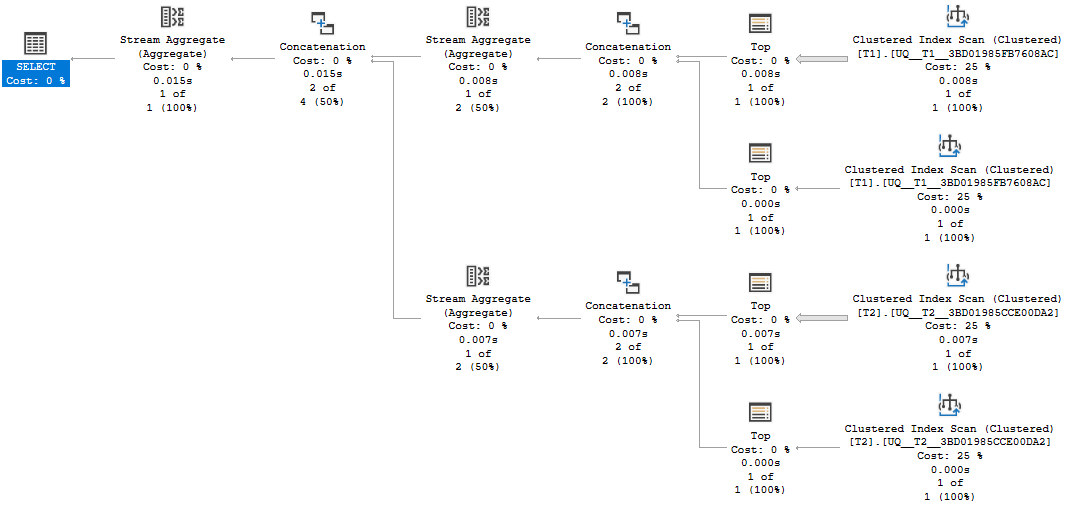
For each table this has two backwards index scans - one with an `IS NULL` predicate and the other with an `IS NOT NULL` predicate. Each scan can stop after the first row is found.
There are a few things not to like about this arrangement.
* That the `IS NULL` and `IS NOT NULL` are implemented with a scan and predicate in the first place rather than a seek.
* Consequently if either all the rows are `NULL` or all `NOT NULL` one of the scans will read all the rows in the table.
* The `IS NULL` scan is backwards ordered despite the fact that `NULL` will appear at the beginning of the index - therefore has to plough through all the `NOT NULL` rows first. If it was ordered forward and a `NULL` appears in the data this would be found after reading one row.
In the real world scenario that spawned this question this involved very large tables with few or no `NULL`s and lead to an extra 5 billion rows collectively being read across 4 tables ([SO Question](https://stackoverflow.com/q/61957385/73226) and [Paste the Plan](https://www.brentozar.com/pastetheplan/?id=BJvsmdSs8) link).
My initial question was **Why is the IS NULL branch there in the first place?**.
For a scalar `MAX` aggregate surely it might as well just ignore these rows and only concern itself with ones matching the `IS NOT NULL` condition?
(adding an explicit `IS NOT NULL` as below does give a more satisfactory plan)
WITH CTE AS
(
SELECT X FROM T1
UNION ALL
SELECT X FROM T2
)
SELECT MAX(X)
FROM CTE
WHERE X IS NOT NULL
Though I realised after some thought that it needs to read the `NULL`s in order to correctly display (or not) the `Warning: Null value is eliminated by an aggregate or other SET operation.` message.
Updated Question **Is this as good as it gets with ScalarGbAggToTop?**.
* Is there any way to coerce it to use seeks instead of scans (`FORCESEEK` can't produce a plan)?
* If it must use scans can they at least be in opposing directions - so the optimal direction for each predicate?
* If this is "as good as it gets" why is this the case? Is it just the transformation happens too late that alternative access paths will never be considered?
* If so couldn't the post optimisation rewrite phase look for scans with seekable predicates on the index used by the scan (that aren't forced scans) and just convert these to seeks? Would this be a sensible request to make?